Triggering Databricks Notebook from Infoworks Bash Node
Part 1: Creating a Databricks Job to Run a Notebook
1: Create the Notebook in Databricks
- Open your Databricks workspace.
- Navigate to the Workspace section and click Create → Notebook.
- Give the notebook a name (e.g., s
ample_Notebook) and select the language (Python, Scala, SQL, etc.). - Write your code in the notebook.
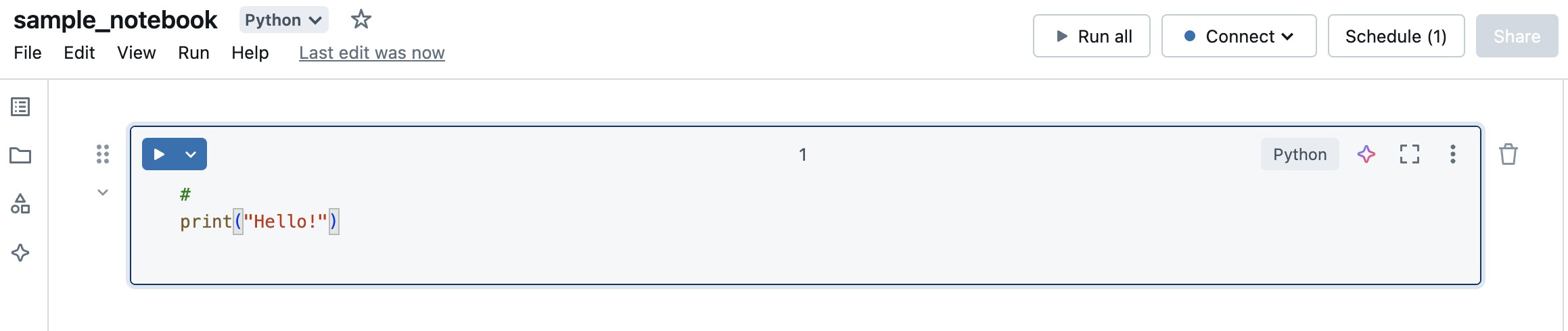
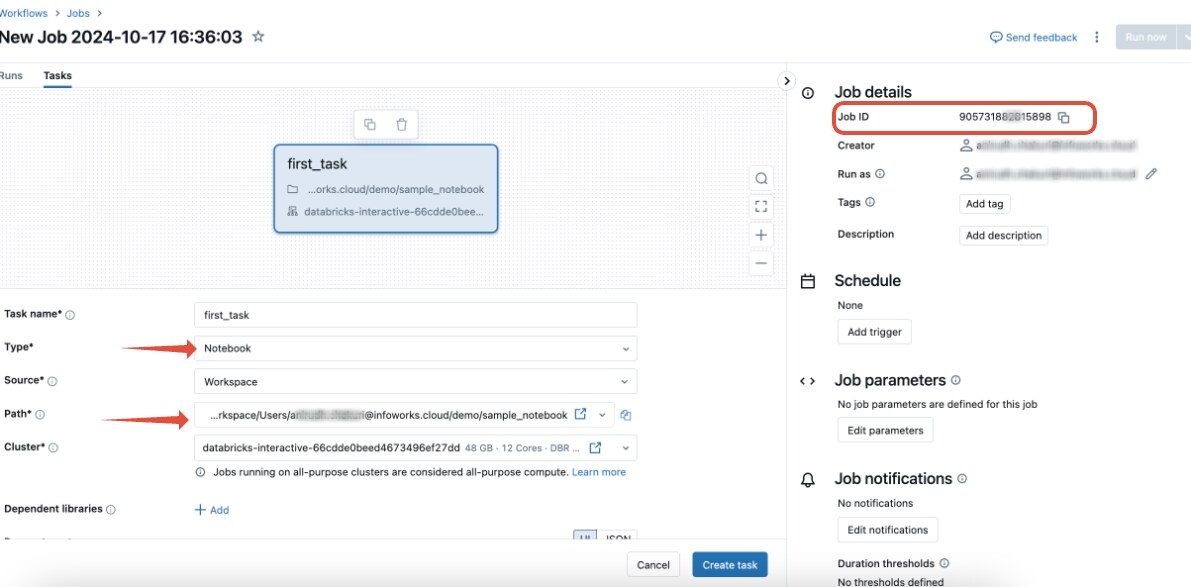
2: Create a Databricks Job to Trigger the Notebook
- Go to Jobs in the Databricks workspace.
- Click Create Job.
- Provide the Job name (e.g.,
Sample_Job). - Under Tasks, click Add task:
- Task name: Notebook Task
- Type: Notebook
- Notebook path: Select the notebook you created (e.g.,
/Workspace/Users/your-notebook). - Optional: Add parameters if required by the notebook.
- Choose the appropriate cluster configuration to run your notebook.
- Click Create to save the job.
- Note the Job ID. You will need this to trigger the job from the Infoworks Bash node.
Part 2: Triggering the Databricks Job from Infoworks Bash Node
Step 1: Authentication Using Azure Service Principal
Databricks requires authentication to trigger jobs via API. We will use Azure Service Principal credentials for this purpose.
Ensure you have the following:
- client_id: Application ID of your Azure Service Principal.
- tenant_id: Azure tenant ID.
- client_secret: Azure client secret. Note: Please store the client secret in Azure Key Vault and create the secret name on Infoworks to use the 'client_secret' securely in bash node.
- Databricks workspace URL: E.g.,
https://.azuredatabricks.net. - Job ID: From the Databricks job created in Part 1.
Step 2: Create Infoworks Bash Node to Trigger the Job and Handle Authentication
Copy the below bash script to Infoworks Bash Node. The script will,
- Authenticate with Azure.
- Trigger the Databricks Job.
- Poll for the job status until it completes.
- Handle token expiry if needed.
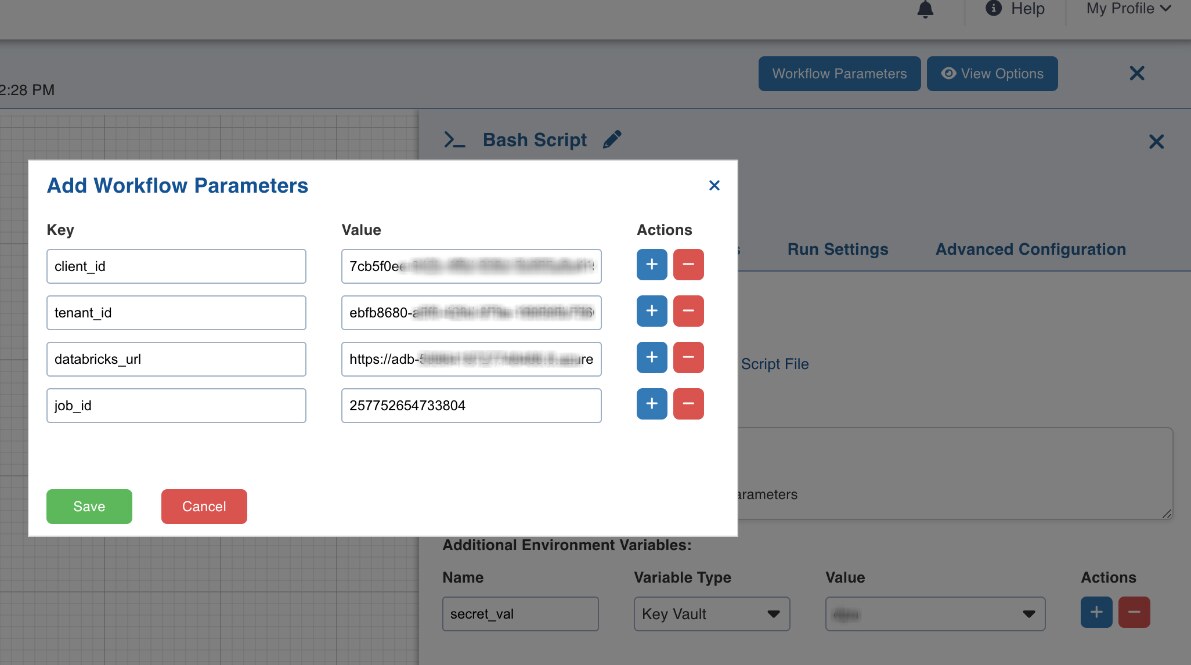
Create Workflow Parameters for below,
client_id
tenant_id
3.databricks_url
4.job_id
Replace secret_val within the bash script on with the env variable name mapped to 'secret name'
Hit Save and Run the workflow.
If you would like to use PAT token to authenticate to Databricks API instead of Azure Service Principal, please use the below script
The workflow parameters required are databricks_url and job_id.
For the PAT toke use Azure key vault use env variable to refer the secret
Was this page helpful?
On This Page
Triggering Databricks Notebook from Infoworks Bash NodeTriggering Databricks Notebook from Infoworks Bash NodePart 1: Creating a Databricks Job to Run a NotebookPart 2: Triggering the Databricks Job from Infoworks Bash Node1: Create the Notebook in Databricks2: Create a Databricks Job to Trigger the NotebookStep 1: Authentication Using Azure Service PrincipalStep 2: Create Infoworks Bash Node to Trigger the Job and Handle AuthenticationCreate Workflow Parameters for below,