You can add custom transformation logic which cannot be fulfilled by any of the out-of-the-box transformation nodes. This is currently supported for only SPARK execution engine.
Prerequisites
Perform the following:
Navigate to the IW_HOME/opt/infoworks/conf/conf.properties file.
Set the extension path in the user_extensions_base_path configuration. For example, user_extensions_base_path=/opt/infoworks/extensions/.
Ensure that the Infoworks user has write access to the folder.
Restart the UI and Data Transformation services.
Creating Custom Transformation
Implement the SparkCustomTransformation API with a class which has a null constructor. For example, SparkCustomTfmSample.java in IW_HOME/examples/custom-transformation/java/sample-code in the Infoworks edge node. You can modify this example java class with the specific transformation requirements. The interfaces to be implemented are packaged in dt-extensions-1.0.jar which you must import in the project. The dt-extensions-1.0.jar is packaged and available with the Infoworks package in the IW_HOME/lib/dt/ folder.
Create a jar for the above project.
Upload the jar (and any external dependencies such as Pheonix jars) to a folder in the Infoworks edge node. For example, /home//pivottransformation/. Jars related to Hadoop, spark etc, will already be available on the Infoworks classpath and hence, not required to be placed in this folder.
NOTES
The Custom Transformation node is not supported for pipelines in snowflake environment.
For the custom target logs to be available in the downloaded cluster logs from the Infoworks custom target pipeline build page, the custom target package should be named
io.infoworks.CustomTarget
Registering Custom Transformation
To register custom transformation, perform the following steps:
Navigate to Admin > Extensions > Pipeline Extensions.
Click Create Pipeline Extension.
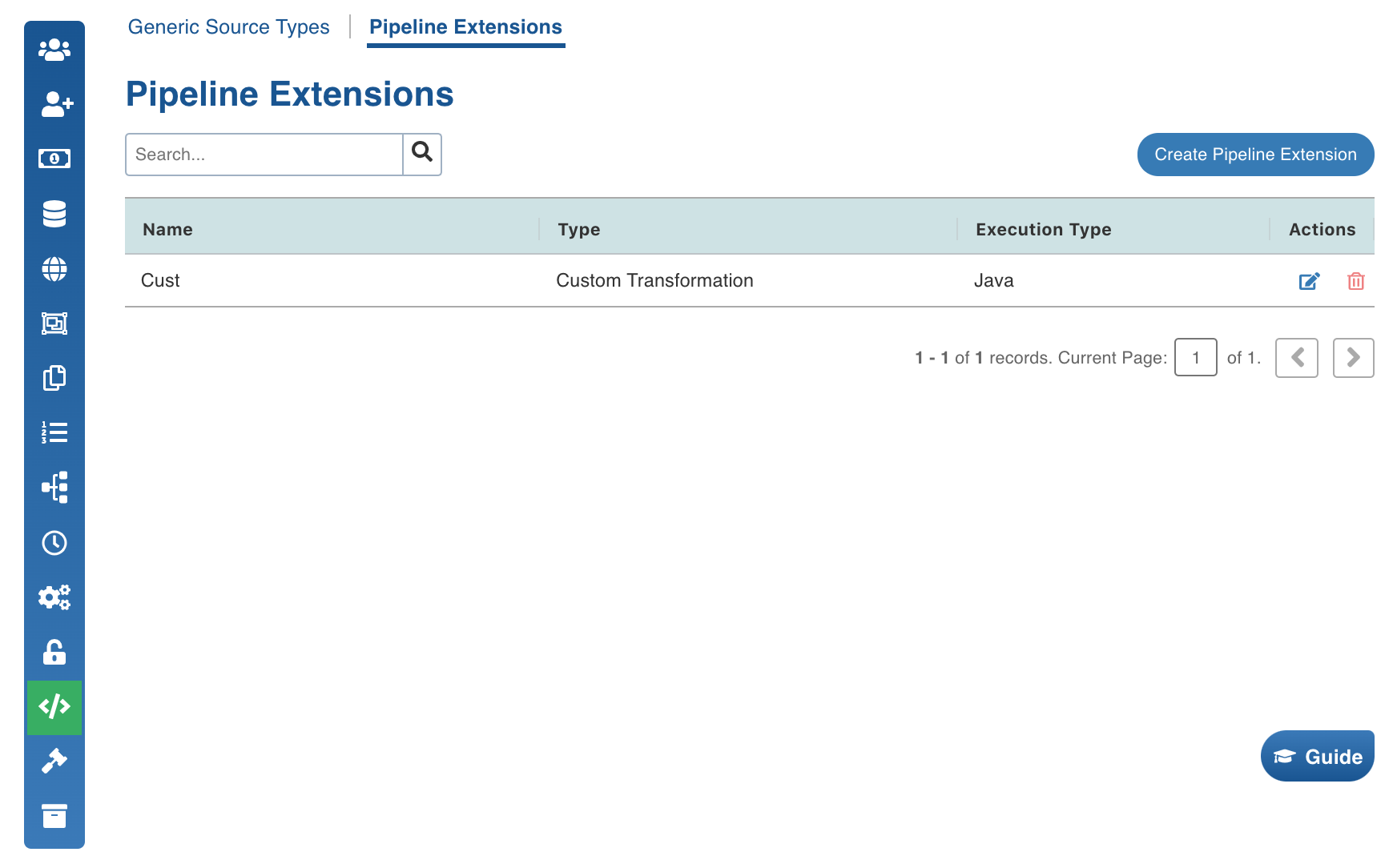
In the Add Pipeline Extension page, enter the following details:
Field | Description |
|---|---|
Extension Type | Choose Custom Transformation. |
Execution Type | Select Java. |
Name | A user-friendly name for the group of transformations under one project. For example, SampleExtension. NOTEUpload the files or enter the path to the folder where the jars have been uploaded. For example, /home//pivottransformation/. The classes implementing the SparkCustomTransformation API which must be available as transformations within Infoworks. |
Alias | A user-friendly alias name for the transformations. For example, Sample. |
ClassName | A fully qualified class name. For example, io.infoworks.awb.extensions.sample.SparkCustomTfmSample. NOTE You can click Add to add multiple pairs of Alias and Class Names. |
Click Save. Once extension is added successfully, the above transformations will be available in Spark pipeline custom transformations node.
Adding Custom Transformation to Domain
To add custom transformation to domain:
Navigate to Admin > Domains.
Click the Manage Artifacts button for the required domain.
Click the Add Pipeline Extensions button in the Accessible Pipeline Extensions section.
Select the Custom Transformation to be made accessible in the domain.
Using Custom Transformation
Following are the steps to apply Custom Transformation node in pipeline:
Open the pipeline editor, drag and drop Custom Transformation and link it with the dependent parent nodes.
Double-click Custom Transformation and click Edit Properties.
In the Properties page, select the appropriate Extension Name and Extension Class from the respective drop-down lists.
Enter a Key and Value which will be added to the transformation node and will be available via UserProperties class from the public void initialiseContext(SparkSession sparkSession, UserProperties userProperties, ProcessingContext processingContext) API.
Click Save.
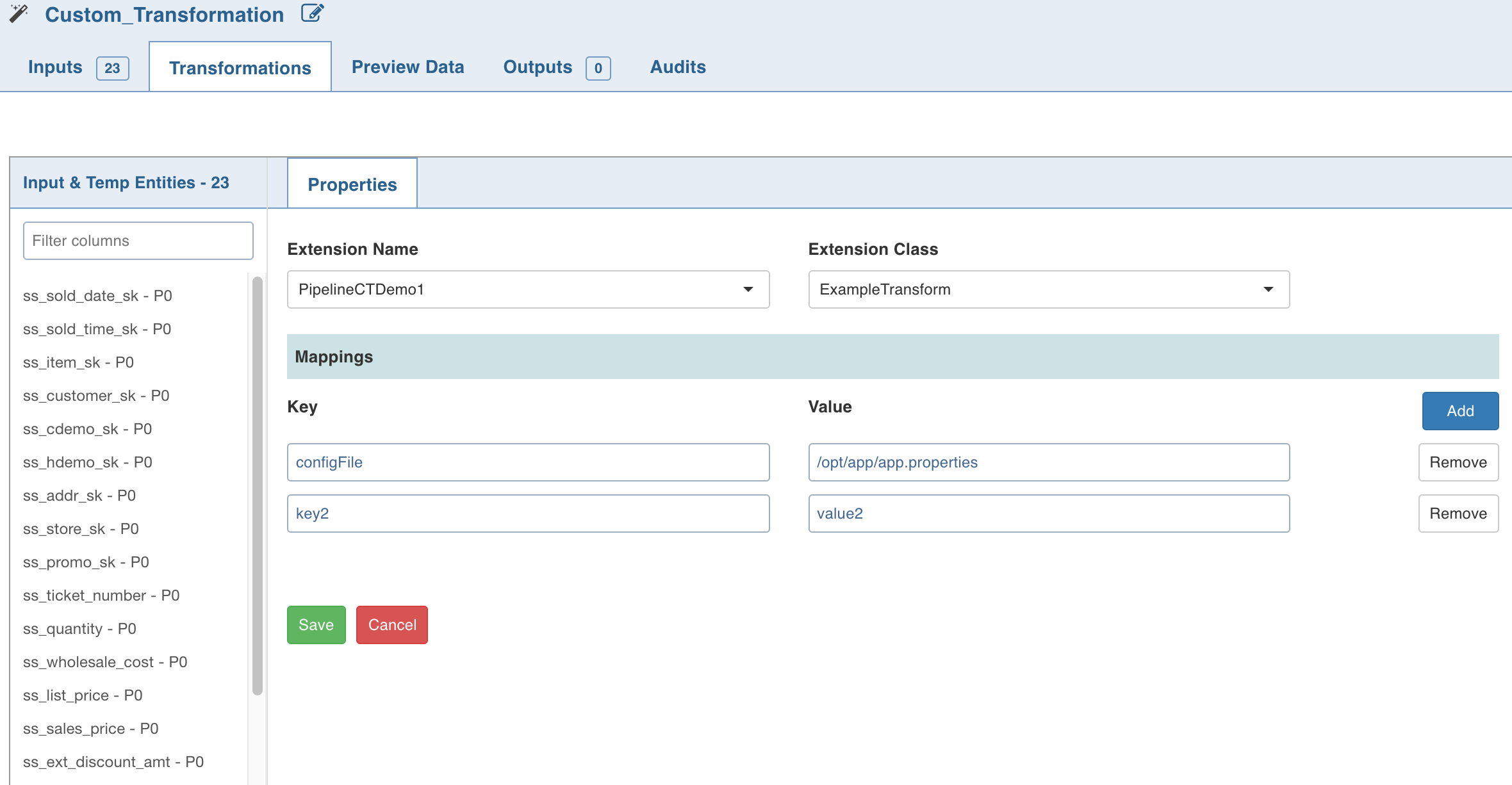
NOTE When using custom transformation, the output columns must be manually added.
Python Custom Transformation
Data Transformation supports writing custom transformations in Python. This can be used to create custom transformations that can be executed as a part of pipelines to allow integration with proprietary or third party libraries.
Creating Python Custom Transformation
NOTE Python Custom Transformations are not supported for K8s based installations.
To create Python Custom Transformation:
Install the python package in IW_HOME/lib/dt/api/python/dt-extensions-python-api-1.0.egg using the following command:
python -m easy_install <path_for_api-1.0.egg>Write the custom transformation logic by implementing the Python API CustomTransformation. To import, add the following statement to the Python custom logic: from api.custom_transformation import CustomTransformation
Example for custom transformation is available at IW_HOME/ examples/custom-transformation/python/sample-code
Create .egg extension file for the python project.
NOTE Use the Java APIs to apply transformation on the input datasets. Internally, py4j is used to communicate to Python custom logic. And, all the provided input data frames are in Java Object form.
Registering Python Custom Transformation
To register Python Custom Transformation:
In Infoworks, navigate to Admin > Extensions > Pipeline Extensions.
Click Create Pipeline Extension.
In the Add Pipeline Extension page, enter the following details:
Field | Description |
|---|---|
Extension Type | Select Custom Transformation. |
Execution Type | Select Python. |
Name | A user-friendly name for the group of transformations under one project. For example, SampleExtension. |
Folder Path | The path to the folder where the .egg file for the python project is saved. For example, /home/transformation/cust.egg. |
Classes | The classes implementing the SparkCustomTransformation API which must be available as transformations within Infoworks. |
Alias | A user-friendly alias name for the transformations. For example, Sample. |
ClassName | A fully qualified class name in the NOTEYou can click Add to add multiple pairs of Alias and Class Names. |
NOTES
Py4j and Pyspark packages must be installed on Python.
Custom transformation with Python runtime is only supported from Python v2.7 onwards.
Configurations
Add the
dt_socket_port_rangeconfiguration in the pipeline advanced configuration to provide available port range (which will be internally used for socket communication). For example, 25810 : 25890. The default range is 25400 to 25500.Add the
dt_socket_max_triesin pipeline advanced configuration to set the maximum number of tries to establish the socket communication. For example, 8. The default value is 10.Set the Python path by adding following configuration to the IW_HOME/conf/conf.properties file
python_custom_executable_path=<python_executable_path>
NOTE If the above configuration is set, the path will be used for Python custom logic. If not set, the default Python version installed on that node will be used.