After creating the pipeline using the required sources, nodes, and transformations, the pipeline is ready to be built.
Following are the steps to build a pipeline:
- Navigate to the Pipeline Design page and click the Build icon.
- Select the Version and click Build Now to build the pipeline version.
- You can click the Build Tables Metadata button to enable import of multiple, sequential pipelines with export configuration.
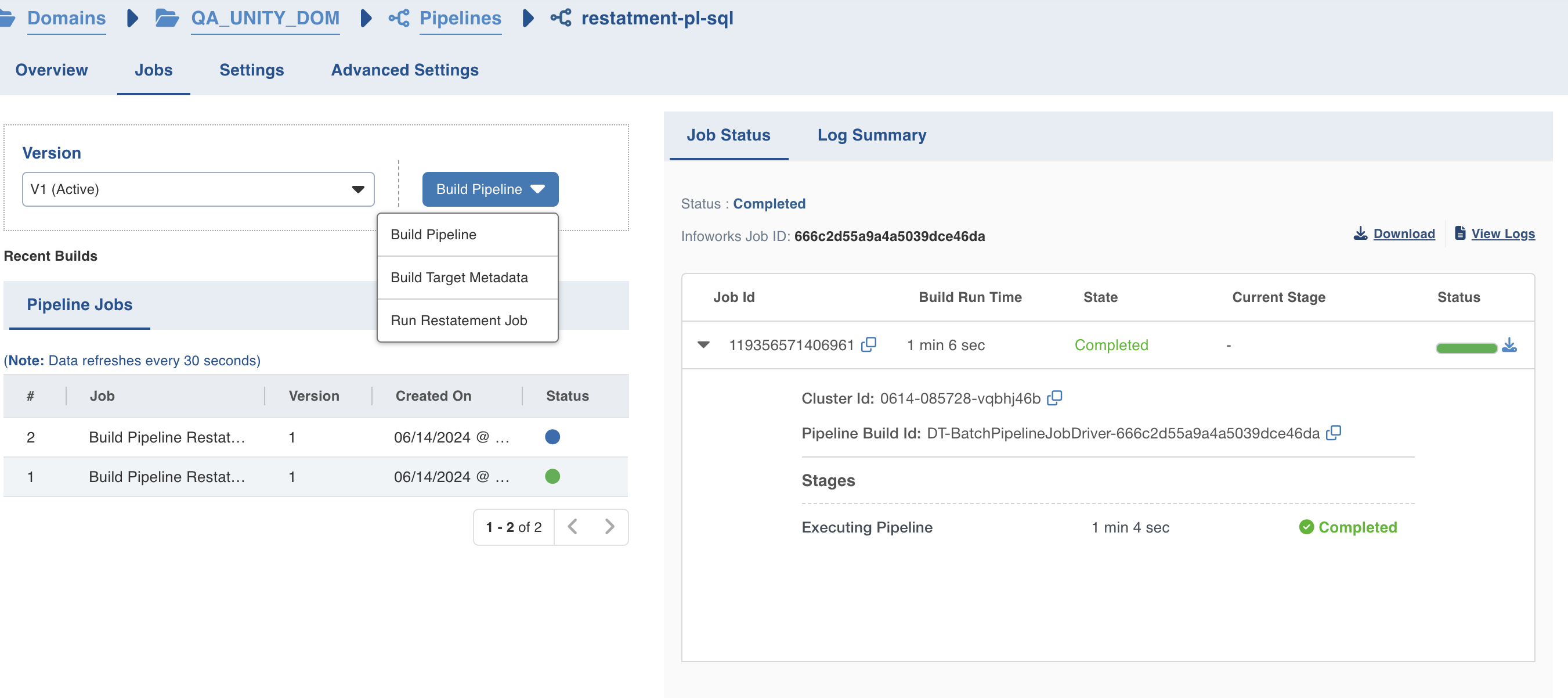
- Click any of the existing builds under the Recent Builds section to view the detailed information of the job. You can view the summary. You can also download the logs of the job.
- You can click the Run Restatement Job button to specify upper and lower watermark limits on a pipeline build job run on load incremental source tables. A window will pop up asking the user to input the upper and lower watermark limits for the source tables with load incrementally enabled. Consequently, the records with watermark value > lower_watermark_limit and <= upper_watermark_limit from the source table will be appended to the target table.
- The DB Jobs tab allows you to debug Databricks jobs using the run details.
UC_COMMAND_NOT_SUPPORTED.WITHOUT_RECOMMENDATION error while running the pipeline build log on unity catalog enabled cluster with shared access as spark execution engine.
Was this page helpful?