The General tab allows you to add/delete configurations, and change the values and descriptions of a configuration key.
The autocomplete feature allows you to select the required configuration from the drop-down list based on your input.
Click the Admin menu, and click Configuration. The General tab is displayed by default.
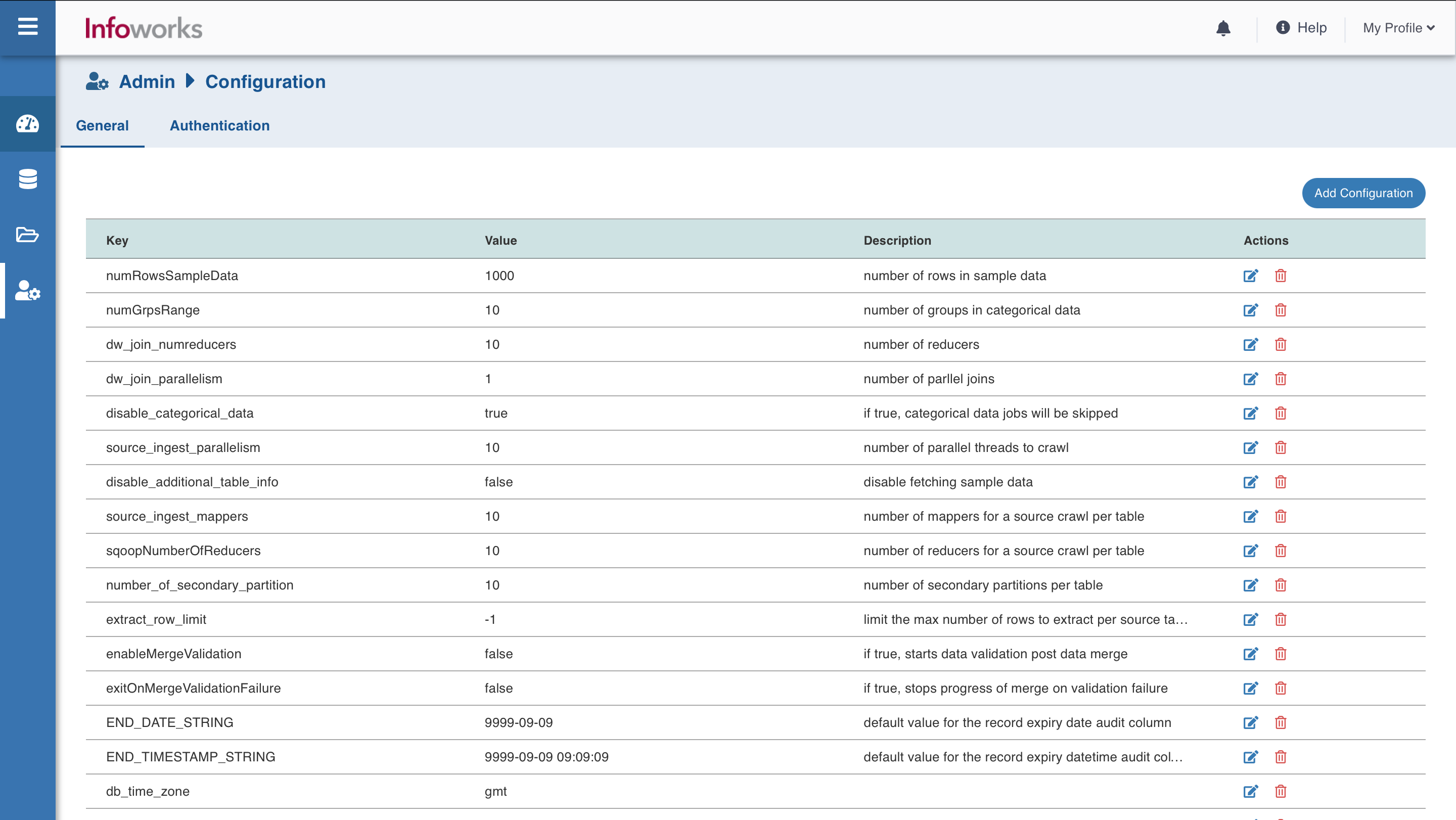
The following table lists all the configuration parameters and their descriptions.
General Configuration Keys and Descriptions
| Configuration Parameter | Description | Default Value |
|---|---|---|
dt_workspace_schema | Schema where Data Transformation stores all intermediate tables. | iw_dt_workspace |
dt_workspace_base_path | HDFS path where Data Transformation stores data for all intermediate data. | /iw/df/workspace |
dt_shared_connection_enabled | Whether to reuse the connection for interactive mode. Typically true for Hive+Tez and false for Hive+MR. | true |
dt_shared_connection_timeout_ms | After how long should an idle shared connection be closed. Shared connection should be enabled. | 180000 |
dt_interactive_exec_pool_size | Thread pool size for executing tasks per request in the interactive mode. | 10 |
dt_interactive_table_maximum_size | Maximum size of any of the intermediate tables in interactive mode. | 10000 |
dt_batch_exec_pool_size | Thread pool size for executing tasks per request in the batch mode. | 5 |
dt_sampling_num_threads | Number of sampling tasks to run in parallel. | 5 |
PIPELINE_SOURCES_AUTO_SYNC_CHECK_DISABLED | If set to true, it disables the error icon on the pipeline editor page indicating source schema mismatch. If set to false, the error icon displays on the pipeline editor page. | |
random_sampling_enabled | Determines whether sample generation, for source or pipeline target, needs to be random. To be disabled when sampling is taking too long to complete or is failing. | true |
LOGMINER_TABLESPACE_NAME | Table space name. | |
use_new_tablespace | To start logminer in different tablespace. | False |
ADVANCED_ANALYTICS_DISABLED | To disable advanced analytics nodes, this should be true. | False |
modified_time_as_cksum | If this is true, the modified time is used to determine if the file has been changed or not. If it is set to false, the actual checksum is calculated. | false |
delete_table_query_enabled | By default, Delete Query feature is available at the table level. Set IW Constant delete_table_query_enabled to false from UI to hide Delete Query feature. | true |
Ufi_max_failure_percentage_per_table | The percentage of files for which the file ingestion is failed before the job is shown as failed. | 0.0 |
MIN_ROWS_FOR_MERGEMR | Minimum number of rows in the current data in a secondary partition for the merge. If a secondary partition has number of rows less than this value, the merge jobs will be combined until they reach this threshold. | 1000000 |
fail_ingestion_on_impala_cache_refresh_failure | Set to true if the ingestion job is to be failed in case Impala cache metadata is not refreshed. | |
iw_hive_ssl_enabled | To Enable or Disable SSL on Hive | false |
iw_hive_ssl_truststore_path | Path to Hive Trust Store File Location | |
iw_hive_ssl_truststore_passwd | Encrypted Password for Trust Store | |
filesystem_scheme | The hdfs path will be pre-populated with the value set in this configuration. The values can be: s3, s3a, s3n, adls, wasb, gs. | - |
dt_batch_sparkapp_settings | This configuration is set to overwrite spark configurations like executor memory, driver memory, etc during pipeline batch build. | |
dt_disable_sample_job | This configuration is set to disable sample jobs after pipeline build. | False |
dt_disable_cache_job | This configuration is set to disable cache jobs after pipeline build. | False |
CREATE_DROP_TARGET_SCHEMA | Used to allow Infoworks to run create database and drop database commands.If this value is set to false, the create database and drop database commands will not be executed. | True |
target_schema_permission | Used to enable or disable creation of database in pipelines.If this value is set to false, creation of database in pipelines will be disabled. | True |
number_of_parallel_jobs_per_entity | The number of jobs that can run in parallel for each entity.Entity refers to either of the following: Source, Datamodel, Cube.For example, if this value is set to 3, then a maximum of 3 source crawls or 3 data model builds or 3 cube builds can occur in parallel. | NA |
dt_auto_exclusion_enabled | Used to set pipeline target column projection optimization on all nodes. | True |
dt_merge_exec_pool_size | Number of concurrent tasks to run while performing merge on pipeline targets. | 5 |
dt_fail_on_null_or_empty_partition_value | Used to fail the pipeline jobs when partition values are Null or Empty. | False |
iw_udfs_dir | Indicates the UDFs directory. | NA |
iw_hdfs_prefix | Default HDFS access protocol prefix. | hdfs:// |
dt_label_auto_cast_enabled | Used to enable Auto Cast mode for Advanced Analytics Model Label Column. | True |
dt_label_cast_type | Used to indicate the default value for Advanced Analytics Model Label Column. | Double |
dt_spark_master | Indicates the Spark master mode. | local |
dt_target_hdfs_cleanup | To retain data on HDFS when the pipeline is removed, set this false. | True |
dt_batch_spark_settings | Semi-colon separated list of Entity level Hive configurations. Applicable for batch mode pipeline build and to generate sample data in source. | key1=value1;key2=value2;key3=value3 |
dt_scd2_granularity | SCD2 record change granularity on timestamp can be Second,Minute,Hour,Day,Month,Year. This can be set using advance configuration to overwrite configuration for all targets at once. | second |
dt_custom_udfs_force_copy | Custom UDFs in pipelines are only copied to HDFS when changes are detected. This configuration is used to overwrite changes to custom UDFs. | False |
dt_disable_sample_job | Used to disable sample job for pipeline targets after pipeline build. | False |
dt_disable_cache_job | Used to disable cache job for pipeline targets after pipeline build . | False |
dt_spark_configfile | Spark configuration file path for Interactive mode Spark pipelines. | /etc/spark2/conf/spark-defaults.conf |
dt_spark_configfile_batch | Spark configuration file path for Batch mode Spark pipelines. | /etc/spark2/conf/spark-defaults.conf |
dt_batch_spark_coalesce_partitions | Spark coalesce configuration to create lesser files while writing to disk. | NA |
dt_disable_current_loader | Custom Transformations cannot be loaded from current class loader. To load Custom Transformation from current classloader, set this configuration to False. | True |
dt_overwrite_log_level | Log Level overwrite at pipeline level.For example, rootLogger=ERROR;io.infoworks=TRACE;infoworks=DEBUG;org.apache.spark=ERROR. | NA |
dt_validation_progress_percent | Used to set the validation process percent in pipeline batch jobs. | 10 |
dt_schemasync_progress_percent | Used to set the Schema Sync progress percent in pipeline batch jobs. | 10 |
dt_spark_merge_file_num | Spark configuration to merge files using Coalesce option on dataframe during merge process. | 1 |
iw_dt_ext_prefix | Pipeline extension prefix. | hdfs:// |
storage_format | Used to set the default storage format value for pipeline target. | ORC |
user_extensions_base_path | Pipeline extension base path. | NA |
SUPPORT_RESERVED_KEYWORDS | Used to enable or disable support for reserved keywords. To enables Hive connection on HDP 3.1, this value must be set to false. | True |
dt_cutpoint_optimization_enabled | Enables caching when the value is set to true. | False |
dt_redshift_s3_uri_scheme | This configuration is provided to specify the URI scheme for the S3 temp dir used in the Redshift connector. | s3a |
dt_target_row_count_enabled | This configuration is to specify if the user wants to get the target row count at the end of pipeline build. | True |
dt_label_auto_cast_enabled | This configuration is for auto casting labels in ML nodes for integers. | True |
dt_label_cast_type | This configuration is to specify the cast type of the table column in ML nodes. | Double |
dt_convert_source_watermark_to_timestamp | This configuration is for generic jdbc sources to convert source watermark column to timestamp. | False |
dt_convert_ _all_source_watermark_to_timestamp | This configuration is for all sources to convert source watermark column to timestamp. | False |
dt_source_type_sybase_iq_comparator_column | This configuration is for identifying the column to be used for fetching the latest records on the basis of timestamp for Sybase sources. | ZIW_OFFSET |
dt_source_ type_oracle_comparator_column | this configuration is for identifying the column to be used for fetching the latest records on the basis of timestamp for Oracle sources. | ZIW_SCN |
dt_source_type_sql_ server_comparator_column | This configuration is for identifying the column to be used for fetching the latest records on the basis of timestamp for Sql Server sources. | ZIW_SOURCE _START_TIMESTAMP |
dt_source _type_db2_comparator_column | This configuration is for identifying the column to be used for fetching the latest records on the basis of timestamp for DB2 sources. | ZIW_SOURCE _START_TIMESTAMP |
sample_data_row_count | Number of rows to be retrieved as part of sample data. | 100 |
sample_data_error_threshold | % of invalid records in sample data after which the sample data will fail | 50 |
file_preview_row_count | Number of rows to be shown for file preview. | 100 |
file_preview_size_limit | Maximum File size for file preview. | 10 (in MB) |
bulk_payload_record_size | Number of records in the payload for each batch of bulk insert. | 6500 |
maxNumOfRows | Maximum number of chunks allowed for segment load. | 2000 |
error_record_threshold | Maximum number of invalid records after which the data crawl will fail. | 1000 |
csv_null_value | Null value for csv file | Null |
is_multi_line_csv | Set it to true if csv file has multilines. | False |
CSV_FILE_ ENCLOSE_CHAR | Character used to enclose the column value. | " |
CSV_FILE_ESCAPE_CHAR | The character used in the delimited files to escape the occurrences of column separator and column enclosed by in data. | \ |
exclude_partition_column_csv_export | If set to true, the output file will not contain the column on which file is partitioned | False |
coalesce_partitions | Set the value to 1 if the output should contain a single file. | 0 |
default_connectors_path | The base path for connectors. | lib/ingestion/connectors/ |
default_core_ingestion_lib_path | Path to the core libraries. | lib/ingestion/core/ |
use_iw_csv_mapper | - | false |
tpt_files_base_path | Base path for all tpt job related file (configs,logs,scripts). | /temp/ |
add_tpt_ log_to_job_log | Add TPT log to job log. | True |
copy_tpt_ log_to_target | Copy tpt log to target. | False |
tpt_select_operator | Operator used for TPT export (EXPORT/SELECTOR). | EXPORT |
tpt_charset | Charset specified in tbuild command. | ASCII |
tpt_cloud_dont_split_rows | DontSplitRows parameter in tpt access modules. | True |
use_tpt_generated_schema | Use TPT generated schema. | False |
tpt_ascii_multiplication_factor | ASCII multiplication factor | 1 |
tpt_utf8_multiplication_factor | UTF8 multiplication factor | 2 |
tpt_utf16_multiplication_factor | UTF16 multiplication factor | 2 |
tpt_export_operator_max_decimal_digits | MaxDecimalDigits attribute in select operator. | 38 |
tpt_export_spool_mode | SpoolMode attribute in select operator. | spool |
tpt_export_block_size | BlockSize attribute in select operator. | 64330 |
tpt_export_tencity_hours | TenacityHours attribute in select operator. | 4 |
tpt_export_retry_interval | TenacitySleep attribute in select operator. | 1 |
tpt_export_max_sessions | MaxSessions attribute in select operator. | 20 |
tpt_export_min_sessions | MinSessions attribute in select operator. | 1 |
enable_tpt_data_encryption | DataEncryption attribute in select operator. | False |
enable_tpt_trace_level | TraceLevel attribute in select operator (true will change it to ALL). | False |
tpt_checkpoint_interval_in_seconds | -Z flag in tbuild command. | 0 |
enable_tpt_log | -o flag in tbuild command. | False |
tpt_cyclic_delivery | -C flag in tbuild command. | False |
tpt_job_restart_limit | -R flag in tbuild command. | 2 |
tpt_shared_ memory_size | -h flag in tbuild command. | 10 |
merge_dedupe_function | De-duplication method used to de-duplicate cdc table (options : WINDOW, ORDER_BY_ DROP_DUPLICATES, SORT_DROP_DUPLICATES) | WINDOW |
handle_deletes_during_merge | - | False |
should_run_dedupe | De-duplicate the cdc data | False |
should_run_de_dup_on_full_load | De-duplicate table during full load job (init and ingest). | False |
get_sample_data_during_schema_crawl | Fetches sample data during metacrawl if set to true. | False |
get_row_count_during_schema_crawl | Fetches row count during metacrawl if set to true. | False |
metacrawl_batch_size | Number of tables to be metacrawled at a time | 100 |
keywords_to_be_renamed_filepath | - | - |
database_object_types_default | Table types to be included for browse source and meta crawl. | TABLE, VIEW, SYNONYM |
keywords_to_be_renamed | - | USING |
TEMP_LOG_TABLE_NAME | Name of the temporary log table created for tables configured for log based ingestion. | LOG_ |
NUMBER_OF_LOG_FILES_TO_LOAD | The configuration used to restrict the number of log files to load in each run of CDC. | -1 |
CHECK_FOR_NULL_LOG_FILE | The key that determines whether we check for null log file path in case of log based ingestion. | True |
ORACLE_ARCHIVE_LOG_INFO_OBJECT_NAME | The name of the view of the oracle archive log info. | sys.v_$archived_ log |
LOG_FILE_SEQUENCE_COLUMN_NAME | The column name of the column that maintains log file sequence. | SEQUENCE# |
IS_SECONDERY_LOG_LOCATION | True if the user has changed the log file location, false otherwise. | False |
include_current_log | The key that determines whether the key with the last log sequence number is included in the query or not. | False |
ORACLE_LOG_ DESTINATION_ID | Destination id of the oracle log in case of secondary log location. | 2 |
SET_NLS_DATE_FORMAT | The key that should be set to true if the user wants to use the NLS_DATE_ FORMAT. | False |
NLS_DATE_FORMAT | This key specifies the default date format to use with the TO_CHAR and TO_ DATE functions.The value of this parameter can be any valid date format mask. | YYYY-MM-DD HH24:MI:SS |
use_new_tablespace | To start logminer in different tablespace. | False |
LOG_MINER_TABLESPACE_NAME | Tablespace name. | logmnrts |
LOGMINER_TEMP_TABLE_TABLESPACE_NAME | Temp Tablespace name. | logmnrts |
LOG_BASED_CDC_LOG_CONCAT_ORDER | - | ASC |
ORACLE_LOG_BASED_CDC_CLEAN_CONTROL_CHARACTERS | - | False |
WIDE_TABLE_ CONCAT_UDF_NAME | - | stragg(sql_redo_ record(sql_redo,query_order)) |
ADD_LOG_BASED_SELECT_QUERY_PARALLELISM | Parallelism factor for select queries for tables configured with log based ingestion. Should be an integer. | False |
SELECT_QUERY_PARALLELISM_FACTOR | Parallelism factor for select queries. Should be an integer. | 1 |
RUN_TEMP_TABLE_STATS | The key that determines whether we get the table stats for the temp table. | False |
remove_extra_single_quote | The key used to remove any extra single quote char found. | True |
escape_escape_char_in_data | The key that determines whether we use escape character while parsing the query. | True |
date_format | Date format of data for log-based cdc. | dd-MMM-yy |
timestamp_format | Time format of data for log-based cdc. | dd-MMM-yy hh.mm.ss a |
is_time_format_needed | The key that determines whether we parse the date to a specific format while parsing the query. | True |
use_jsql_and_expression | Should use jsqlparser AndExpression or not. | True |
UNCOMMITED_TIME_PERIOD | The uncommitted records older than this time period (specified in days) are deleted. | 7 |
oracle_timezone_as_region | If true, we set oracle.jdbc.timezoneAsRegion property to true. The property checks if the node connecting to oracle database is in some specified timezone list. | False |
oracle_date_functions | Can specify any oracle date functions to handle date and time data easily and more effectively. | TO_DATE,TO_ TIMESTAMP |
oracle_logbase_date_parsed_format | Oracle log based date parse format. | yyyy-MM-dd |
oracle_logbase_timestamp_parsed_format | Oracle log based timestamp parsed format. | yyyy-MM-dd HH:mm:ss.SSSSSS |
temp_table_stats_percent | Used to run temp table stats query. | 20 |
temp_table_stats_degree | Used to run temp table stats query. | 8 |
temp_table_ index_name_one | Prefix name used to create index on few columns of temp table. | IW_ |
CREATE_TEMP_TABLE_PARALLELISM | Parallelism factor for temp table queries. Should be an integer. | 1 |
create_index_on_temp_table | An index is created on the temp table if set to true. | True |
FILTER_ORACLE_COMMITTED_TRANSACTIONS | Option DBMS_LOGMNR.COMMITTED_ DATA_ONLY is set for the LogMiner session. This enables you to filter out rolled back transactions, transactions that are in progress, and internal operations. | False |
ENABLE_DDL_TRACKING | Option DBMS_LOGMNR.DDL_ DICT_TRACKING is set for the LogMiner session to enable ddl tracking. DDL tracking enables LogMiner to successfully track structural changes made to a database object, such as adding or dropping columns from a table. | False |
purge_retries_num_attempts | Number of retries if there is a failure during purge job. | 5 |
should_send_notifications | The key that determines whether the user gets notified of events like, delete source, meta crawl, full load and cdc jobs, and so on. | True |
governor_request_timeout_sec | Timeout for governor requests | 30 |
custom_mappings | 10000 | |
oem_quote_character | Quote character to be used for oem source queries. | " |
oem_key_default_value | Default key value used for oem connectors to connect. | XKR3Rwo8S5mLT57IGZ56uTIT/hcBbC1ZnYB+jYE1ZU02dCzvxakdhnuXFEY1I6HGmpiMg/AeHZJFuhb4w8bYkmQwFBkL8S+mM1bZva/zLbvxFG4kmRH4g1yFKQ== |
meta_db_limit | It is required for fetching number of records in single call from metadb(mongo) if number of records are too large, and can’t be fetched in single call from metadb due to resources issue. Currently its being used while getting list of files in sources, if there files in order of 100k, we are fetching that detail in chunk, that limit describe that chunk size | 1000 |
meta_crawl_row_count | 100 | |
topic_preview_row_count | Number of rows to be shown for topic preview. | 100 |
kafka_erro_ threshold_default | This configures that the crawl fails if there are more error records than this configured limit, or more than successful records. | 5 |
kafka_max_num_records_default | Maximum records to consider for schema crawl. | 20000 |
kafka_streamin_frequency_num_default | Time unit for frequency type for schema crawl. | 10 |
kafka_streamin_frequency_type_default | Streaming frequency for schema crawl. | Secs |
kafka_streaming_mode_default | Streaming mode for schema crawl . Options are micro_batch and polling. | micro_batch |
confluent_client_dns_lookup | Controls how the client uses DNS lookups. | use_all_ dns_ips |
confluent_consumer_num_retries | This configures the Confluent consumer retries for metacrawl. | 5 |
confluent_kafk_sample_data_error_threshold_default | Maximum number of invalid records after which the sample data will fail. | 50 |
invalid_record_threshold | This configures that the crawl fails if there are more error records than this configured limit, or more than successful records. | 5 |
confluent_deserializer_class | io.infoworks.connectors.streaming.confluent.kafka.utils.ConfluentJsonDeserializer - By default this class will be used to deserialize json messages which uses confluent KafkaJsonDeserializer. | |
cancel_job_via_file | If this is set to true the streaming job will be stopped by stopping the streaming query. | false true (for databricks) |
logical_date_format | The format for specifying logical date for Avro messages. | YYYY-MM-dd |
logical_time_millis_format | The format for specifying logical time in milliseconds for Avro messages | HH:mm:ss.SSS |
logical_time_micros_format | The format for specifying logical time in microseconds for Avro messages | HH:mm:ss.SSSSSS |
logical_timestamp_millis_format | The format for specifying logical timestamp in milliseconds for Avro messages | yyyy-MM-dd HH:mm:ss |
logical_timestamp_micros_format | The format for specifying logical timestamp in microseconds for Avro messages | yyyy-MM-dd HH:mm:ss |
local_timestamp_millis_format | The format for specifying local timestamp in milliseconds for Avro messages | yyyy-MM-dd HH:mm:ss |
local_timestamp_micros_format | The format for specifying local timestamp in microseconds for Avro messages | yyyy-MM-dd HH:mm:ss |
confluent_error_threshold_default | This configures that the schema crawl fails if there are more error records than this configured limit, or more than successful records. | 5 |
confluent_max_num_records_default | Maximum records to consider for schema crawl. | 20000 |
confluent_streaming_frequency_num_default | Time unit for frequency type for schema crawl. | 10 |
confluent_streaming_frequency_type_default | Streaming frequency for schema crawl. | secs |
confluent_streaming_mode_default | Streaming mode for schema crawl in confluent. Options are micro_batch and polling. | micro_batch |
confluent_auto_offset | This configures the start point for a query. The "earliest" option ingests all the messages from the beginning, "latest" option ingests the messages that are pushed to topic after the query has started (which are the latest messages). | earliest |
use_custom_deserializer | If set, the confluent_deserializer_ class value will be used for json message format. I the json messages are added to confluent topic using string serializer then set this configuration to false. | True |
table_retrieval_mechanism | - | session_catalog |
sfdc_socket_timeout_for_rest | Socket timeout when fetch mechanism is REST. | 2000 |
sfdc_bulk_timeout | Timeout when fetch mechanism is bulk. | 600000 |
sfdc_batch_size_for_rest | - | 1200000 |
error_record_cache_count | - | 100000 |
in_memory_cache_count | - | 100000 |
serialize_hadoop_conf | - | True |
sfdc_timeout | Connection timeout for salesforce soap api login. | 1200000 |
ingestion_spark_configs | - | Null |
ingestion_service_worker_pool_size | - | 20 |
environment_home | - | /infoworks |
run_optimize_table | Run OPTIMIZE table command for the table. | False |
optimize_delta_write | This sets property for delta tables “delta.autoOptimize.optimizeWrite = true”. | False |
auto_compact_delta_table | This sets property for delta tables “delta.autoOptimize.autoCompact = true”. | False |
kafka_starting_offsets | This configures the start point for a query. The "earliest" option ingests all the messages from the beginning, "latest" option ingests the messages that are pushed to topic after the query has started (which are the latest messages). | Earliest |
kafka_min_partitions | This configures the desired minimum number of partitions to read from Kafka. By default, Spark has a 1-1 mapping of topic partitions to Spark partitions consuming from Kafka. | Null |
kafka_group_id | This configures the Kafka Group ID to be used in the Kafka consumer, while reading data from Kafka. By default, each query generates a UUID for reading data. | Null |
kafka_optimize_query_batch_interval | This configures the number of batches after which the optimize query will be queried | 10 |
kafka_consumer_num_retries | This configures the Kafka consumer retries for metacrawl. | 5 |
kafka_meta_ crawl_error_threshold | This configures the threshold percentage for the meta crawl to fail. Meta crawl fails if the percentage of error records received is more than this configured value. | 50 |
fail_on_data_loss | This configures whether the query must be failed when there is a possibility that the data is lost (For example, topics are deleted, or offsets are out of range). | False |
kafka_extra_properties | This configures the start point for a query. The "earliest" option ingests all the messages from the beginning, "latest" option ingests the messages that are pushed to topic after the query has started (which are the latest messages). | Null |
ui_url | The host for sending datacrawl notification. | Localhost |
ui_port | The port for sending datacrawl notification. | 3000 |
meteor_https_enabled | - | False |
meteor_https_port | - | 2000 |
rdbms_fetch_size | The JDBC fetch size, which determines how many rows to fetch per round trip | 1000 |
mongo_date_time_format | DateTime format for mongo. | yyyy-MM-dd'T'HH:mm:ss.SSS'Z' |
mongo_timezone | time zone for mongo | UTC |
cdc_comparator_key | - | >= |
tpt_segment_file_ts | - | 000000000 |
file_split_size | - | 134217728 |
data_types_ with_precision_scale | Datatypes which have precision and scale. | 2,3 |
default_precision | Default precision of numeric and decimal datatypes. | 38 |
default_scale | Default Scale of numeric and decimal datatypes. | 18 |
use_query_for_meta_crawl_generic_jdbc | Whether to use query for metacrawl for generic jdbc sources. | True |
stop_streamin_polling_frequency | - | 15 |
use_type_cast | - | False |
parquet_infer_schema | Whether to infer schema for parquet source. | False |
delete_segment_staging_tpt | Whether to delete the staging area for teradata segments. | True |
restricted_visibility_mode | When True, sources are private and accessible by other users only via domain based access. When False, only role based access is checked. | False |
iw_spark_app_conf | Spark configuration key to be used across ingestion and transformation | spark.key.1=value1 ; spark.key.2=value2 (values are separated by “;”) |
export_metrics_capture | Configuration option to retrieve the export metrics. By default, this option is set to false. Set the value to true to retrieve metrics for export jobs. | False |
tpt_file_escape_char | EscapeTextDelimiter attribute in TPT Data Connector operator | \ |
tpt_file_quote_escape_char | EscapeQuoteDelimiter attributte in TPT Data Connector operator | \ |
tpt_file_enclose_char | OpenQuoteMark and CloseQuoteMark attributes in TPT Data Connector operator | " |
tpt_delimiter | TextDelimiter attribute in TPT Data Connector operator | | |
tpt_io_buffer_size | IOBufferSize attribute in TPT Data Connector operator | 1048575 |
tpt_use_hex_escape_chars | Use Hex escape character | False |
tpt_cloud_prefix | Prefix base name for intermediate cloud in Data Connector initialization string | iw |
tpt_cloud_single_part_file | SinglePartFile attribute in Data Connector initialization string | False |
tpt_cloud_compress | Use compressed files for TPT dump | False |
tpt_cloud_buffer_count | BufferCount attribute in Data Connector initialization string | Null |
tpt_cloud_buffer_size | BufferSize attribute in Data Connector initialization string | Null |
tpt_cloud_connection_count | ConnectionCount attribute in Data Connector initialization string | 10 |
tpt_files_base_path | Base path for all tpt job related files (configs,logs,scripts) | /tmp/ |
tpt_cloud_config_directory | Relative path for TPT config files | tpt/cloudConfig |
tpt_cloud_max_object_size | MaxObjectSize attribute in Data Connector initialization string | 1024M |
tpt_trace_level | TraceLevel attribute in Data Connector initialization string | Null |
tpt_https_proxy | HttpsProxy attribute in GCP Access module initialization string | Null |
tpt_add_script | Add TPT script to cluster logs | False |
csv_comments_identifier | This is used to set a comment character in CSV files. | # |
treat_empty_string_as_null | When set to false, empty string will be fetched as empty string, and not null | True |
fetch_null_records | When set to true, records will be fetched with null watermark value | False |
dt_interactive_service_cluster | You can choose whether to run the worker interactive service on control plane or data plane. Set the value to Databricks to run it on data plane. | Local |
dt_snowflake_default_query_size_kb | Snowflake has a limitation of query size not being greater than ~520 KB. You can create cut points within the pipeline and break the query into smaller ones if the limit is being exceeded. | 500 KB |
dt_sf_cutpoint_optimization_enabled | Set this value to False to disable the cut point optimisation. | True |
should_delete_tables_source_delete | When set to True, if the table is Infoworks managed, it will be deleted from snowflake database on deletion of the source. But if the table is user managed, it will just be truncated and not deleted from the Snowflake database. | False |
dt_preview_data_disabled | When set to True, preview data is disabled globally and user gets a warning message "Preview data is disabled". | False |
add_columns_for_alter_table | When set to True, the alter table queries runs to modify the exported table, or else user can alter the tables manually as per their need. | True |
managed_mongo | When set to True, MongoDB is on Infoworks edge node, or else it is on MongoDb Atlas or external Mongo. | True |
is_quiescent_enabled | When set to True puts the system in quiescent mode, any new jobs that are submitted will move to pending state. Any jobs that are already running will have no affect and continue till completion. Pause and resume of workflow will not be allowed and newly submitted run of the workflow will pause the whole workflow itself. | False |
system_name | This indicates the page title so that the user can correctly identify the IWX system/environment. | NULL |
dt_bigquery_session_project_id | Use this configuration to specify the project id to use for the BigQuery session created for the BigQuery target jobs in dt. | <gcp_project_name> |
ingestion_bigquery_session_project_id | Use this configuration to specify the project id to use for the BigQuery session created for the BigQuery target jobs in Ingestion. | <gcp_project_name> |
enable_schema_sync | To enable schema evolution from source to Ingestion target table, set the configuration to true. | True |
databricks_init_script_workspace_directory | The configuration can used to set the location of init-scripts under databricks workspace. | /Shared |
consider_scale_user_managed | For scale comparison for decimal and integer numbers on snowflake (for user managed table) | false |
consider_column_datatype_user_managed | For comparing column datatype between iwx column type and target column type on snowflake (for user managed table) | true |
consider_column_map_size_user_managed | For comparing number of columns between iwx target table on snowflake (for user managed table) | true |
consider_precision_user_managed | For precision comparison for decimal and integer numbers on snowflake (for user managed table) | false |
test_job_ids | The configuration takes comma separated job ids, when set in quiescent mode system will try to run the provided job ids. | - |
test_workflow_ids | The configuration takes comma separated workflow ids, when set in quiescent mode system will enable pause and resume for the particular workflows, user then can resume those workflows, newly submitted run of the workflow will not pause the workflows provided. | - |
dt_use_gte_for_load_incremental | For configuring load incremental source table to use “>=” filter condition for the watermark limits while reading from the source during the pipeline build jobs | false |
use_ingestion_time_as_watermark | For configuring source nodes in the pipeline to use ziw_target_timestamp as a watermark column | false |
workflow_email_attachment_size_limit | Defines the maximum size allowed for a single email attachment in MB | 20 |
workflow_email_total_attachments_size_limit | Defines the maximum cumulative size of all attachments in a single email in MB | 50 |
iw_messaging_max_request_size_mb | Max size of the request body for messaging service | 51 |
Update password for MongoDB and HIVE
To encrypt and update password for MongoDB or HIVE in the Infoworks system, perform the following:
- Execute the following interactive bash script:
$IW_HOME/apricot-meteor/infoworks_python/infoworks/bin/infoworks_security.sh -encrypt -p - Enter the new plain text password when prompted.
- Copy the encrypted password displayed in the result and update in the Infoworks conf.properties file located in the $IW_HOME/conf folder.