Configure Source and Target -> Select Tables -> Configure Synchronization -> Onboard Data
This section explains how to onboard data from a CDATA source, to the data lake by configuring the compute environment and base location.
Before initiating the onboarding process, you must ensure to define an Environment. For more information on how to define the Environment, refer to Managing Environments section.
The Infoworks onboarding process includes the following steps:
Configure Source and Target
After defining the compute environment, you can set up a CDATA source for ingestion, that includes configuring the connection URL, user credentials, and target location where you want to onboard the data.
To define the source and target, you must perform the following steps:
- Select the Data Sources icon on the left navigation and click Onboard New Data.

- Select the CDATA Source in the Source Type, from the Categories list. For example, to create an Act CRM data source, select Act CRM.
Now, you can configure the source connection properties and select the data environment where you want to onboard the data.
Configure the following fields:
| Source Fields and Description | |
|---|---|
| Source Field | Description |
| Source Name | A name for the source that will appear in the Infoworks User Interface. The source name must be unique and must not contain space or special characters except underscore. For example, Customer_Details. |
| Connection URL | The connection URL through which Infoworks connects to the database. For details on connection URL, refer to the individual CDATA source sections. |
| Username | The username for the connection to the database. |
| Authentication Type for Password | Select the authentication type from the dropdown. For example, Infoworks Managed or External Secret Store If you select Infoworks Managed, then provide Authentication Password for Password. If you select External Secret Store, then select the Secret which contains the password. |
| Snowflake Warehouse | Snowflake warehouse name. Warehouse is pre-filled from the selected snowflake environment and this field is editable. |
| Target Fields and Description | |
|---|---|
| Target Field | Description |
| Data Environment | Select the data environment from the drop-down list, where the data will be onboarded. |
| Storage | Select from one of the storage options defined in the environment. |
| Base Location | The path to the base/target directory where all the data should be stored. |
| Schema Name | The schema name of the target. |
| Snowflake Database Name | The database name of the Snowflake target. |
| Staging Schema Name | The name of the schema where all the temporary tables (like CDC, segment tables etc) managed by Infoworks will be created. Ensure that Infoworks has ALL permissions assigned for this schema. This is an optional field. If staging schema name is not provided, Infoworks uses the Target Schema provided. |
| Use staging schema for error tables | Click this checkbox to create history tables in the staging schema. |
| BigQuery Dataset Name | Dataset name of the BigQuery target. |
| Staging Dataset Name | The name of the dataset where all the temporary tables (like CDC, segment tables, and so on) managed by Infoworks will be created. Ensure that Infoworks has ALL permissions assigned for this dataset. This is an optional field. If staging dataset name is not provided, Infoworks uses the Target dataset provided. |
| Use staging dataset for error tables | Click this checkbox to create history tables in the staging dataset. |
| Make available in infoworks domains | Select the relevant domain from the dropdown list to make the source available in the selected domain. |
You may choose to click the Save and Test Connection button to save the settings and ensure that Infoworks is able to connect to the source system.
Click Next to proceed to the next step.
Select Tables
There are two ways in which tables can be selected, browsing the source to choose the tables and configuring a custom query.
- Browse Source: You can browse the source to select the tables to be onboarded as per requirement. You can add more tables later.
- In the Browse Source tab, select the source tables you want to onboard the data.
- Filter the tables by Source schema, Table Name, and Table Type and refresh the list.
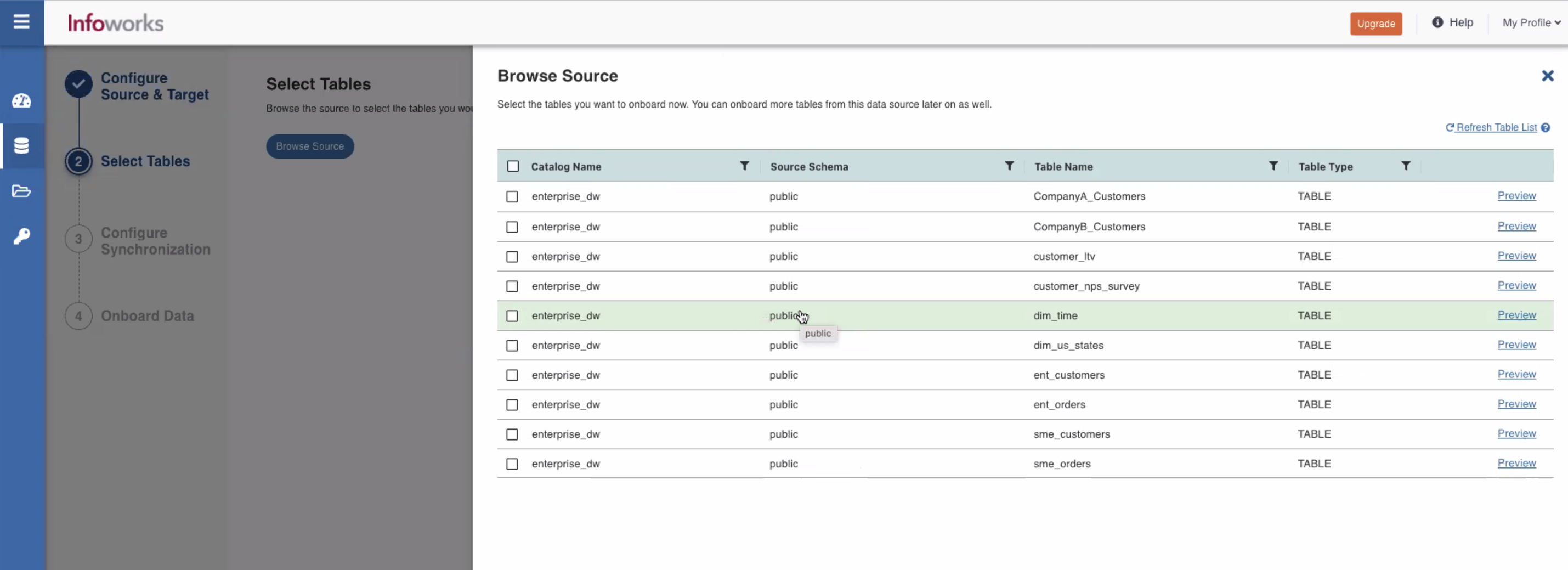
- Specify the Target Schema Name and Target Table Name in the respective fields for the data environment.
- Click Next to proceed.
- Add Query As Table: You can create a table using a custom query so that you can ingest a subset of the data from a table in the source or data belonging to more than one table in the source.
- Click the Add Query As Table tab, and click Add Query As Table button. A pop-up window appears.
- Enter the Query, Target Schema Name and Target Table Name in the relevant fields, and click Save.
- If you want to add more tables, click on Add Query As Table and repeat step 2.
- Click Next to start the metadata crawl.
Configure Synchronization
The tables are automatically set to Full refresh by default.
To modify the configurations and synchronize the table that is onboarded:
- Click the Configuration link for the desired table.
- Enter the configuration details as mentioned below under "Configure a Table" section.
Configuring a Table
With the source metadata in the catalog, you can now configure the table for CDC and incremental synchronization.
- Click the Configure Tables tab.
- Click on the required table from the list of tables available for the source.
- Provide the ingestion configuration details.
| Field | Description |
|---|---|
| Ingestion Configuration | |
| Query | The custom query based on which the table has been created. |
| Ingest Type | The type of synchronization for the table. The options include full refresh and incremental. |
| Natural Keys | The combination of keys to uniquely identify the row. This field is mandatory in incremental ingestion tables. It helps in identifying and merging incremental data with the already existing data on target. |
| Incremental Mode | The option to indicate if the incremental data must be appended or merged to the base table. This field is displayed only for incremental ingestion. The options include append, merge and insert overwrite. |
| Watermark Column | The watermark column to identify the incremental records. |
| Ingest subset of data | The option to configure filter conditions to ingest a subset of data. For more details, see Filter Query for RDBMS Sources |
| SQL Queries | |
| Select Query | The additional inputs required with a select clause, like optimization hints or lock changes. The default value is
|
| Target Configuration | |
| Target Table Name | The name of the target table. The name cannot contain special characters except underscore. |
| Schema Name | The name of the target schema. The name cannot contain special characters except underscore. |
| Storage Format | The format in which the tables must be stored. The options include Read Optimised (Delta) and Write Optimised (Avro). |
| Partition Column | The column used to partition the data in target. Selecting the Create Derived Column option allows you to derive a column from the partition column. This option is enabled only if the partition column datatype is date or timestamp. Provide the Derived Column Function and Derived Column Name. The data will be partitioned based on this derived column. |
| Optimization Configuration | |
| Split By Column | The column used to crawl the table in parallel with multiple connections to database. Split-by column can be an existing column in the data. Any column for which minimum and maximum values can be computed, can be a split-by key. Select the Create Derived Split Column option and provide the Derived Split Column Function to derive a column from the split-by column. This option is enabled only if the split-by column datatype is date or timestamp. The data will be split based on the derived value. |
| Generate History View | The option to preserve data in the history table. If enabled, after each CDC, the data will be appended to the history table. |
There are some constraints in the exposed SQL query, which are not the generic sql constraints:
- The column value to be matched in the where clause if is of string data type the value have to be enclosed in single quotes but not in double quotes.
Query that fails:select ${columnList} from "infoworks-new"."active_tokens" where '_id'="5f843fde639afc3ab0f2bf39"``
Query that succeeds :select ${columnList} from "infoworks-new"."active_tokens" where '_id'='5f843fde639afc3ab0f2bf39'``
- If there are any column name that starts with '_' then the column name have to be used with a single quotes in the exposed query.
Query that fails:select ${columnList} from "infoworks-new"."access_logs" WHERE _id ='f2e08b8df0dbf1fd113bbc73'``
Query that succeeds:select ${columnList} from "infoworks-new"."access_logs" WHERE '_id' ='f2e08b8df0dbf1fd113bbc73'``
Adding a column to the table
After metadata crawl is complete, you have the flexibility to add a target column to the table.
Target Column refers to adding a target column if you need any special columns in the target table apart from what is present in that source.
You can select the datatype you want to give for the specific column
You can select either of the following transformation modes: Simple and Advanced
Simple Mode
In this mode, you must add a transformation function that has to be applied for that column. Target Column with no transformation function applied will have null values in the target.
Advanced Mode
In this mode, you can provide the Spark expression in this field. For more information, refer to Adding Transform Derivation.
Onboard Data
The final step is to onboard the tables. You can also schedule the onboarding so that the tables are periodically synchronized.
| Fields | Description |
|---|---|
| Table Group Name | The name of the table group that is onboarded. |
| Max. Parallel Tables | The maximum number of tables that can be crawled at a given instance. |
| Max Connections to Source | The maximum number of source database connections allocated to this ingestion table group. |
| Compute Cluster | The compute cluster that is spin up for each table. |
| Overwrite Worker Count | The option to overwrite the minimum and maximum worker values configured in the compute template. |
| Number of Worker Nodes | The number of nodes that can be spun up in the cluster. |
| Snowflake Warehouse | Snowflake warehouse name. For example, TEST_WH. |
| Onboard tables immediately | Select this check box to onboard the tables immediately. |
| Onboard tables on a schedule | Select this check box to onboard the tables on a schedule at a later point in time. |
Click Onboard Data at the bottom right of the screen to onboard the data.
On the Success message pop-up, click View Data Catalog to onboard additional data or click on View Job Status to monitor the status of the onboarding job submitted.
Additional Options
Refer the sections below, if you want to configure additional parameters for the source.
Additional Connection Parameters
You can set additional connection parameters to the source as key-value pairs. These values will be used when connecting to the source database.
To add additional connection parameters:
- Click Add and enter the Key and Value fields.
- Select Encrypt Value to encrypt the value. For example, Password.
- Select the Is Active check box if the parameter is to be set to Yes.
- Click Save to save the configuration details. The parameters appear in the Additional Connection Parameters section.
- You can edit or delete the parameters using the Edit or Delete icons.
Configuration Migration
For migrating configurations of a CDATA source table, see Migrating Source Configurations
Optional: Source Extensions
To add a source extension to process the data before onboarding, see Adding Source Extension
Optional: Advanced Configuration
To set the Advanced Configurations at the source level, see Setting Source-Level Configurations.
Optional: Subscribers
You can notify the Subscribers for the ingestion jobs at the source level. To configure the list of subscribers, see Setting Ingestion Notification Services
Delete Source
Click Delete Source to delete the source configured.
Onboard Additional Tables
To onboard more tables from the same data source, follow these steps.
- Navigate to the already configured data source
- Click the Onboard More Tables button
- Select the tables and provide necessary details
Enabling OAuth for CDATA Drivers
The CData JDBC drivers provide support for retrieving, refreshing, and storing authentication tokens. CDATA offers connectors like REST based connectors that support OAuth authentication. The OAuth authentication uses access tokens and refresh tokens to make connections to the source application. OAuth can be enabled for all the CDATA drivers that support OAuth.
Since Infoworks jobs run on multiple workers, each worker needs access tokens and refresh tokens so that they can access the data from the required application. In case the access token expires or is invalid, the driver gets a new access token using the refresh token.
The OAuth support implements the ITokenStore interface offered by CDATA and uses this interface to retrieve or modify tokens. Infoworks uses MongoDB storage to implement this interface to read or write tokens, as all the workers have access to the MongoDB storage.
Depending on the type of CDATA driver, there are different types of authentication that can be used to interact with the source application. You can find the details of different kinds of authentication that CDATA offers in the CDATA documentation for the driver you’re using.
The two most commonly used authentication mechanisms for the CDATA drivers, and how to enable them are described below:
To enable OAuth
Follow the steps mentioned below to set up the source for the CDATA connector you want to use. This example shows how to enable OAuth for the CDATA REST connector:** **
- Create a source for the CDATA driver as described in this section above.
- Click Add under Additional Connection Parameters section.
- The REST connector uses a .rsd file that defines the schema of the corresponding database. The .rsd file propagation to all the workers must be handled by the user by using the init scripts that runs on each worker while bringing up the corresponding cluster.
- Enter the key-value pair for all the additional parameters to be set. For example:
OAuthSettingsLocation: The location where the OAuthSettings file gets created which contains the access token and refresh token. Since the Infoworks jobs run on multiple workers, propagating the settings file to all the workers must be handled by the user.
AuthScheme = OAuth:Setting this parameter to OAuth enables the OAuth authentication for the source.
INITIATEOAUTH = GETANDREFRESH: By default the value is GETANDREFRESH. However, the user can overwrite this parameter at any time. If this parameter is set, then the driver will update and refresh the token if the token expires.
Infoworks offers a solution where the user does not need to handle the propagation of theOAuthSettings file across all the workers by storing the access and refresh tokens in Infoworks MongoDB which is accessible by all the workers. To use this feature, the user does not have to set anything but the AuthScheme = OAuth param. The OAuthSettingsLocation and INITIATEOAUTH parameters are set from the Infoworks backend.
- Click Save to save the configuration parameters set.
- Configure the tables as described in the section Configuring a Table.
- Ingest the data by selecting the .rsd file and click Ingest.
- Enter the details in the Ingest the Data screen as described in the section Ingesting Data.
Step Result: On job completion, the data is ingested to the target storage.
To enable OAuthJWT
Follow the steps mentioned below to set up the source for the CDATA connector you want to use. This example shows how to enable OAuthJWT for the CDATA Google BigQuery connector using a service account json file.
- Create a source for the CDATA driver as described in this section above.
- Click Add under Additional Connection Parameters section.
- Enter the key-value pair for all the following additional parameters to be set.
AuthScheme = OAuthJWT: Setting this parameter to OAuth enables the OAuthJWT authentication for the source, which authenticates to a service account using a JWT certificate.
INITIATEOAUTH = GETANDREFRESH: The default value is GETANDREFRESH. However, the user can overwrite this parameter. On setting this parameter, the driver will update and refresh the token if the token expires.
OAuthJWTCertType = GOOGLEJSON and OAuthJWTCert : location of the json file : Setting these parameters will facilitate using the json file from the location of the json file set as the OAuthJWTCert parameter. But again since Infoworks jobs run on multiple workers, the json file will be required to be on all the workers at the same location that is set as the OAuthJWTCert parameter.
OAuthJWTCertType = GOOGLEJSONBLOB and OAuthJWTCert : the content of the json file: Setting these parameters will directly pass the json file contents to the driver to authenticate and there is no need to put the json file on all the workers anymore.
- Click Save to save the configuration parameters set.
- Configure the tables as described in the section Configuring a Table.
- Ingest the data by selecting the table and click Ingest.
- Enter the details in the Ingest the Data screen as described in the section Ingesting Data.
Step Result: On job completion, the data is ingested to the target storage.