Data transformation pipelines can create and incrementally synchronize data models and tables to Azure CosmosDB. Azure CosmosDB is Microsoft’s globally-distributed, multi-model database service for managing data at planet-scale.
Following are the steps to apply Cosmos DB Target node in pipeline:
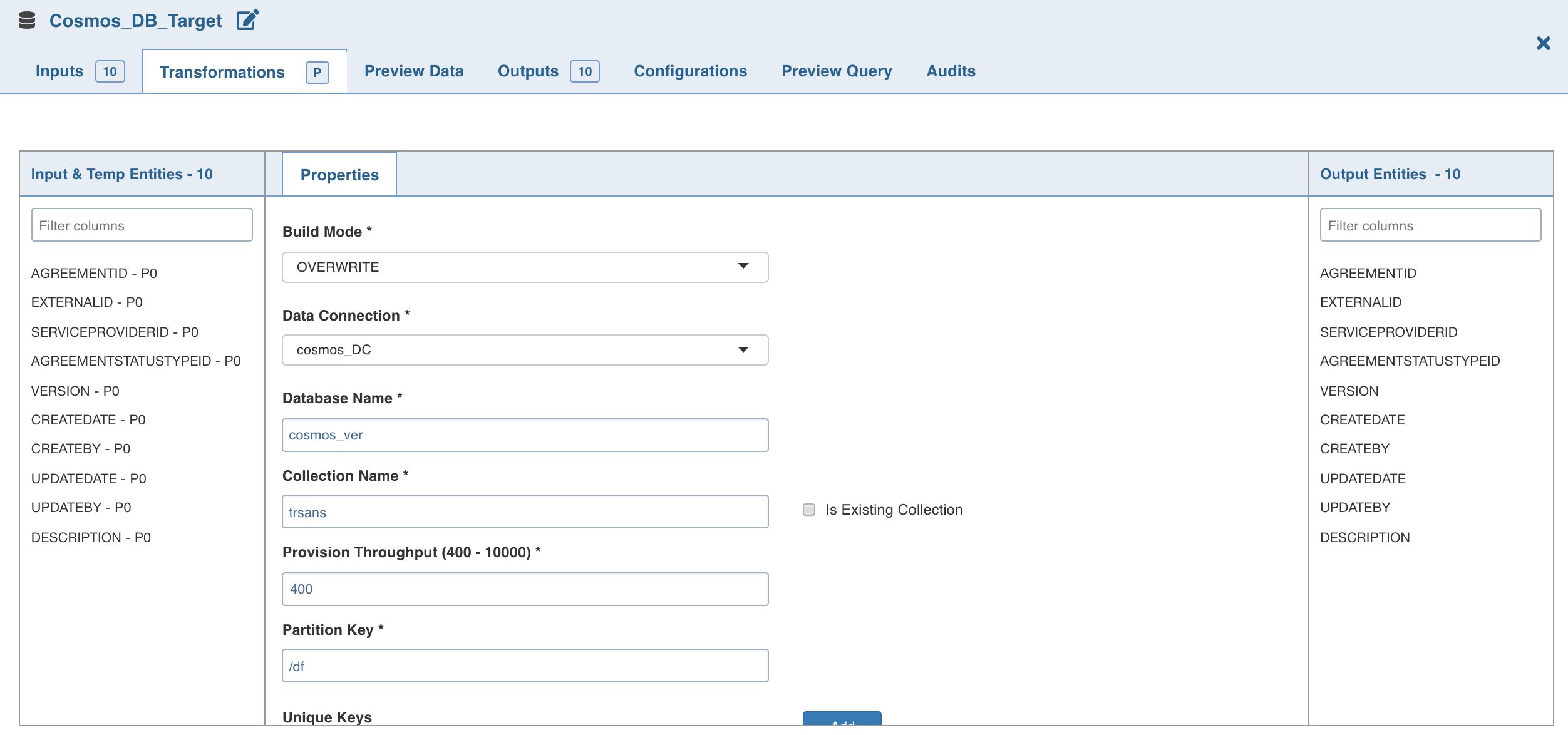
Double-click the Cosmos DB Target node. The Properties page is displayed.
Click Edit Properties.
Properties
Field | Description |
|---|---|
Build Mode | The options include overwrite, append, merge and insert-overwrite. Overwrite: Drops and recreates the Cosmos DB collection. Append: Appends data to the existing Cosmos DB collection. Merge: Merges data to the existing Cosmos DB collection. Insert-Overwrite : Overwrites all the rows based on combination of natural keys (OR condition) and inserts new rows. |
Data Connection | Data connection to be used by the Cosmos DB target. |
Database Name | The name of an existing Cosmos DB target where the tables will be exported. |
Collection Name | Collection to which the documents must to be written. |
Is Existing Collection | Enable this option if the documents must be appended/merged to the existing/provided collection. If unchecked, a new collection will be created. |
Provision Throughput (400 - 10000) | Provision throughput for the container created. The default value is 400. |
Partition Key | The partition key on the Cosmos DB collection to be created. Partition key must be in path format for the JSON document which is to be written to Cosmos DB, for example, /employee/employee_age. |
Unique Keys | A unique key policy is created when an Azure Cosmos container is created. Unique keys ensure that one or more values within a logical partition is unique. Unique key must be in the path format for the JSON document which is to be written to the Cosmos DB, for example, /employee/employee_age. |
NOTES
ID column is mandatory for merge mode.
ID column must only be string.
ID column must not be present for append mode.
Following are the datatypes supported for Cosmos DB (same as JSON datatypes):
String: Double-quoted Unicode with backslash escaping.
Number: Double-precision floating-point format in JavaScript. Exponential notation and integers are supported. Floating point numbers, decimal datatype in Hive, and numbers as strings are not supported.
Boolean: True or false.
Array: Ordered sequence of values.
Value: This can be a string, a number, true or false, null, etc.
Object: Unordered collection of key- value pairs (Example: Struct in hive)
Null: Empty value
Date time in Cosmos: Azure Cosmos DB does not support localization of dates. So, DateTimes must be stored as strings. The recommended format for DateTime strings in Azure Cosmos DB is
YYYY-MM-DDThh:mm:ss.sssZwhich follows the ISO 8601 UTC standard.Hive Timestamp and Date is written as Unix Timestamp in Cosmos DB.