Creating a SalesForce Source
For creating a SalesForce source, see Creating a Source. Ensure that the Source Type selected is SalesForce.
Setting a SalesForce Source
For setting a SalesForce source, see Setting Up a Source.
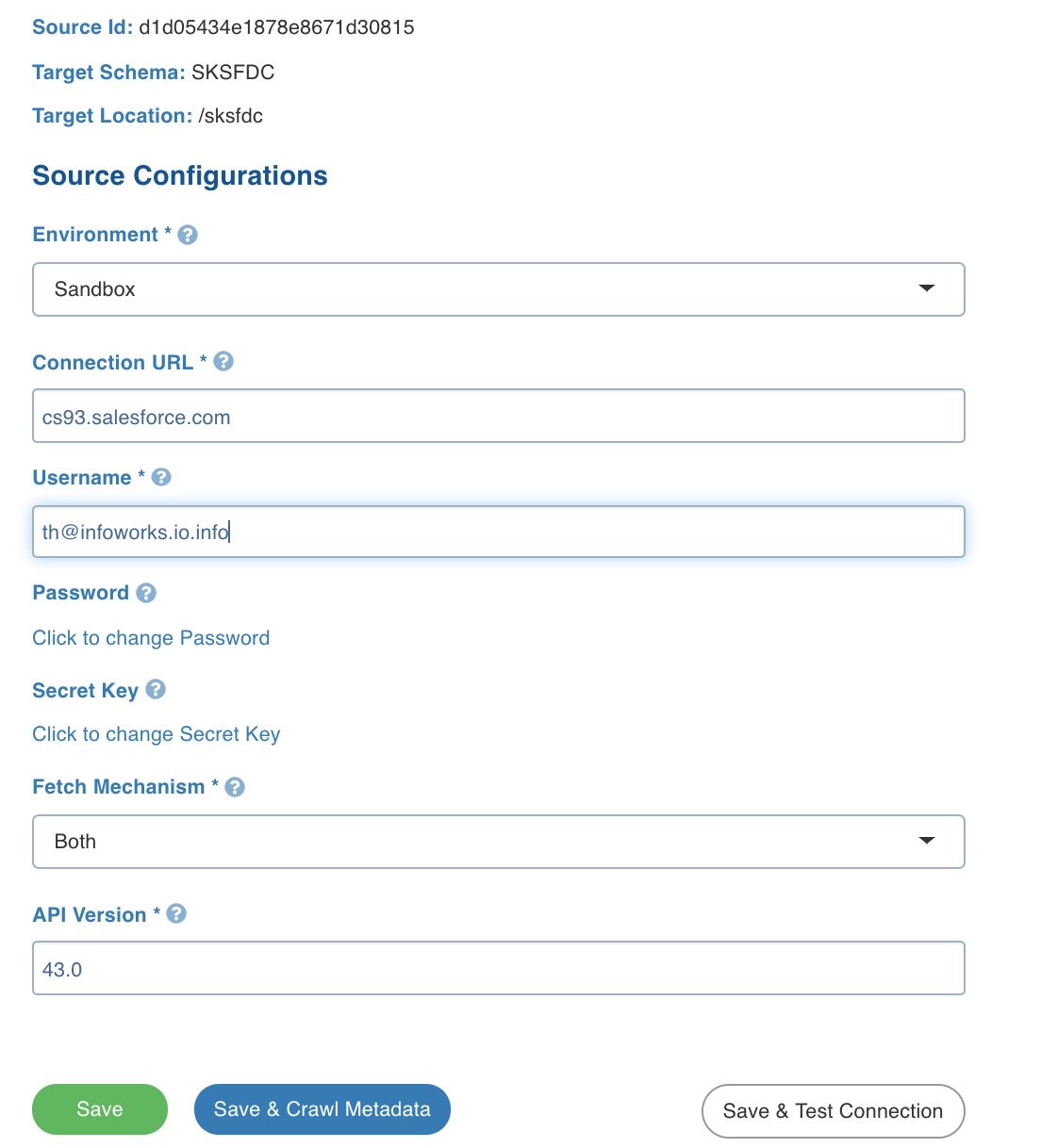
SalesForce Configurations
Field | Description |
|---|---|
Environment | The Salesforce environment Production or Sandbox. |
Connection URL | The connection URL through which Infoworks connects to the Salesforce instance. |
Username | Salesforce login user name. |
Password | Salesforce login password. |
Secret Key | Salesforce connected application secret key. |
Fetch Mechanism | The fetch mechanisms include Bulk, REST and Both. For details, see SalesForce Fetch Mechanism. |
API Version | Salesforce API version. |
SalesForce Fetch Mechanism
Infoworks supports the following methods to crawl data from Salesforce:
Ingestion via Salesforce REST API
Ingestion via Salesforce Bulk API
REST API
Infoworks supports data ingestion via Salesforce REST API. The Salesforce REST API provides data in a paginated manner, where one API response provides the URL of the next API call. Ingestion via REST API is slower compared to bulk API but also provides features like Salesforce Custom Fields and Column Addition. This is the recommended method to crawl data via Infoworks.
Bulk API
Ingestion via Bulk API is faster and must be used in cases where data volumes are high. SalesForce Bulk API provides options to dump data into CSV for faster ingestion. Bulk API also allows data crawled to be parallelised using option like PK chunking. However, Ingestion via bulk API does NOT support the Custom fields and Column Addition features.
Configuring a SalesForce Table
For configuring SalesForce tables, see Configuring a Table.
Ingesting SalesForce Data
For ingesting SalesForce source data, see Onboarding Data.
Ingest Configurations
Field | Description |
|---|---|
Ingest Type | The type of synchronization for the table. The options include full refresh and incremental. |
Update Strategy | This field is displayed for only incremental ingestion. The options include append and merge. NOTE For incremental ingestion, the watermark column will be SystemModTimestamp. |
Natural Keys | The combination of keys to uniquely identify the row. This field is mandatory in incremental ingestion tables. It helps in identifying and merging incremental data with the already existing data on target. |
Storage Format | The format in which the tables much be stored. The options include:Read Optimised (Delta),Write Optimised (Avro). |
Target Table Name | Name of the target table. |
Partition Column | The column used to partition the data in target. |
Fetch Mechanism | The fetch mechanisms include Bulk and REST . |
Enable PK Chunking | The option to enable PK chunking for the table. If enabled, SalesForce splits data based on the primary key and data will be fetched in parallel. |
Generate History View | The option specifies whether to preserve data in the history table. After each CDC, the data will be appended to the history table. |
Error Tables
During data crawl, the data that cannot be crawled will be stored in an error table, <tablename>_error.
Known Issue
By default, the Sample Data section displays the datatype as String for every column.