General Configuration
To configure a table, perform the following steps:
Click the Configure Tables tab.
Enter the ingestion configuration details.
Click Save.
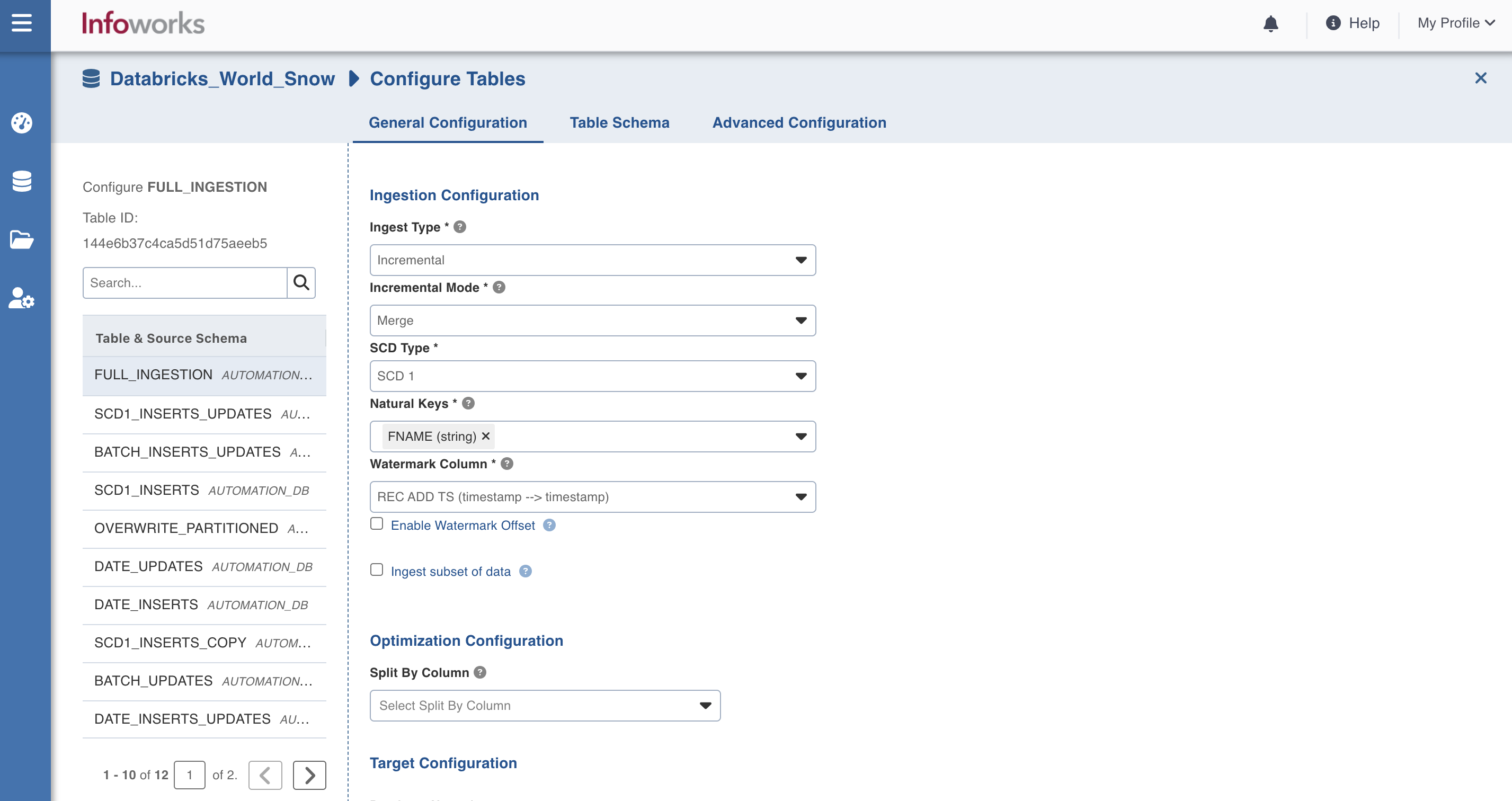
Ingestion Configurations
Field | Description |
|---|---|
Query | The custom query based on which the table has been created. The option is available only for RDBMS, Generic JDBC and CDATA sources. NOTE This field is only visible if the table is ingested using Add Query as Table. |
Ingest Type | The type of synchronization for the table. The options include full refresh and incremental. |
Natural Keys | The combination of keys to uniquely identify the row. This field is mandatory in incremental ingestion tables. It helps in identifying and merging incremental data with the already existing data on target. NOTE At least one of the columns in the natural key must have a non-null value for Infoworks merge to work. |
Incremental Mode | The option to indicate if the incremental data must be appended or merged to the base table. This field is displayed only for incremental ingestion. The options include append and merge. |
Incremental Fetch Mechanism | The fetch mechanism options include Archive Log and Watermark Column. This field is available only for Oracle log-based ingestion. |
Watermark Column | The watermark column to identify the incremental records. |
Use JDBC for This Table | The option to ingest data from Teradata via JDBC driver, if the table cannot be crawled by TPT, for any reason. This option is available for Teradata TPT ingestion. |
Ingest subset of data | The option to configure filter conditions to ingest a subset of data. This option is available for all the RDBMS and Generic JDBC sources. For more details, see Filter Query for RDBMS Sources. |
SQL Queries
Select Query: The additional inputs required with a select clause, like optimization hints or lock changes. The default value is SELECT ${columnList} FROM <schemaName>.<tableName>, where, ${columnList} is the placeholder for all the columns to be queried and <schemaName> and <tableName> will be pre-filled with the appropriate values. This option is available only for Generic JDBC sources.
NOTE Ensure to use the correct SQL Query syntax as per the DB used.
Target Configuration
Field | Description |
|---|---|
Target Table Name | The name of the target table. |
Storage Format | The format in which the tables must be stored. The options include Read Optimised (Parquet),Read Optimised (ORC), and Write Optimised (Avro). LIMITATION The table stored in Read Optimised (ORC) format can only be queried using spark, and not hive. |
Partition Column | The column used to partition the data in target. Selecting the Create Derived Column option allows you to derive a column from the partition column. This option is enabled only if the partition column datatype is date or timestamp. Provide the Derived Column Function and Derived Column Name. Data will be partitioned based on this derived column. |
Detect Schema Change | This checkbox detects if a new column is added. |
Schema Change Behavior | This dropdown provides the list of responses you can choose for the added columns. The responses are: Ignore Column Addition and Notify on Job Failure. Ignore Column Addition: If you select this value, the job won’t fail and it won't add an additional column to the target. Notify on Job Failure: If you select this value and a column is added, the job will fail and an error message which says, “Error in sync schema” will appear on top of the page. |
Optimization Configuration
Field | Description |
|---|---|
Split By Column | The column used to crawl the table in parallel with multiple connections to database. Split-by column can be an existing column in the data. Any column for which minimum and maximum values can be computed, can be a split-by key. Select the Create Derived Split Column option and provide the Derived Split Column Function to derive a column from the split-by column. This option is enabled only if the split-by column datatype is date or timestamp. The data will be split based on the derived value. |
Is Wide Table | The option to be enabled when any insert, update or delete statement in logs can exceed 4000 characters. |
Table Schema
You can view the following pages under table schema:
Editing Table Schema
You can edit the target datatype of columns using the following steps:
Click the Data Catalog menu and click View Source for the required source.
Click the Configure button for the required table.
Click the Table Schema tab and edit the target data type for required columns. The Databricks metastore table will be created with the specified datatypes.
The Options field allows you to edit the precision and scale of the specific column.
You can select a relevant column and click Manage Column to Exclude, Include or Bulk Edit.
Select Include if you want the column to be a part of the target.
Select Exclude if you want the column to be excluded from the target.
Select Bulk Edit to edit the precision and scale of all the columns.
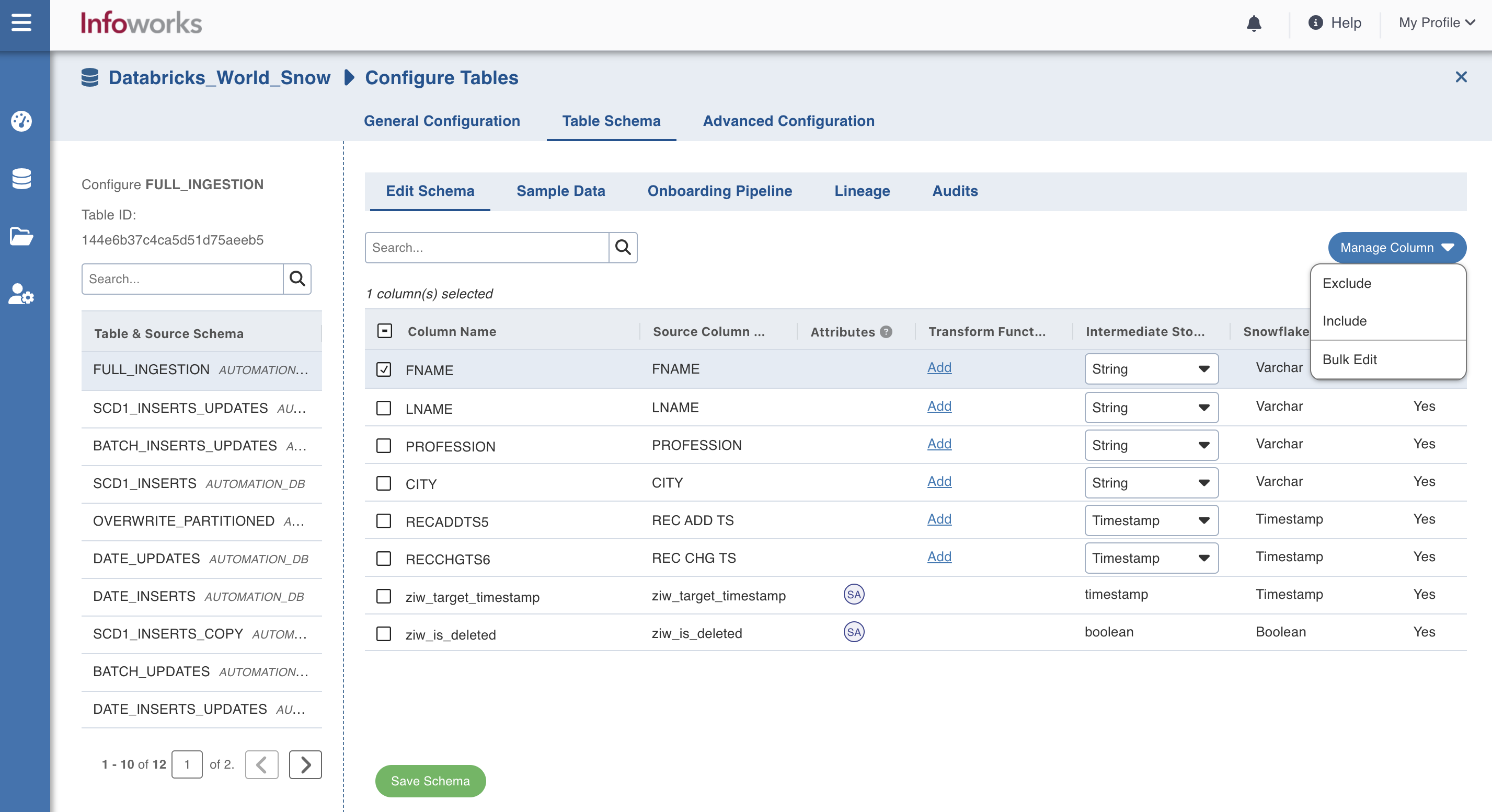
NOTE The Include and Exclude options are available only for Snowflake and BigQuery targets.
Click Save Schema.
Following are the datatype conversions supported:
Source Datatype | Target Datatype |
|---|---|
String | Boolean, Integer, Float, Double, Long, Decimal, Date, Timestamp.Following are date and timestamp formats supported:Date: yyyy-MM-ddTimestamp: yy-MM-dd hh:mm:ss |
Boolean | String |
Integer | Float, Double, Long, Decimal, String |
Float | Double, Long, Decimal, String |
Double | Float, Long, Decimal, String |
Long | Float, Double, Decimal, String |
Decimal | Integer, Float, Long, String |
Date | String |
Timestamp | String |
Byte | String |
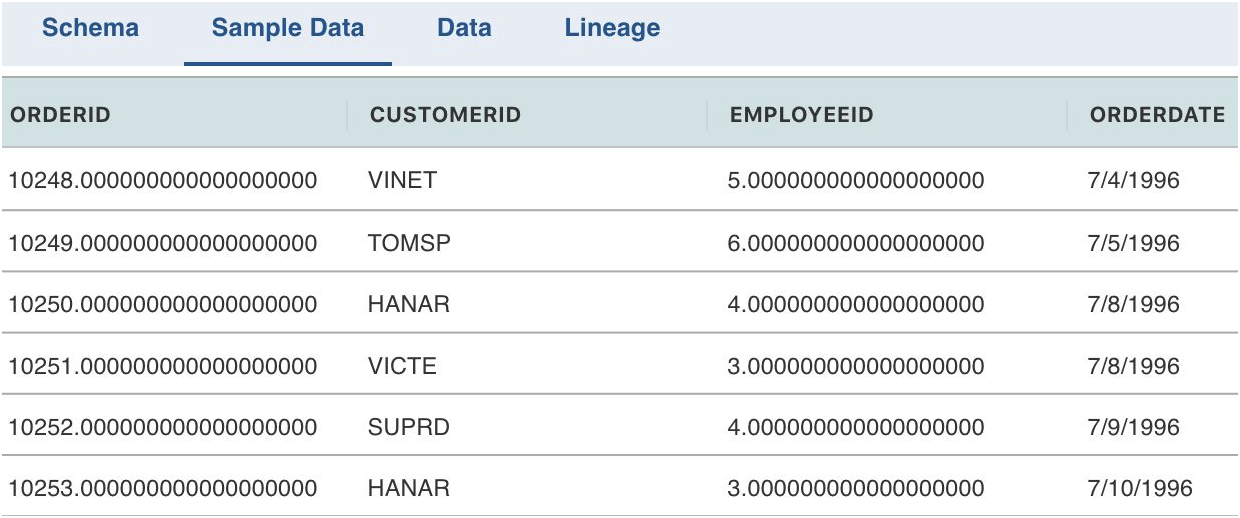
Viewing Sample Data
The Sample Data page includes the sample data of the source table.
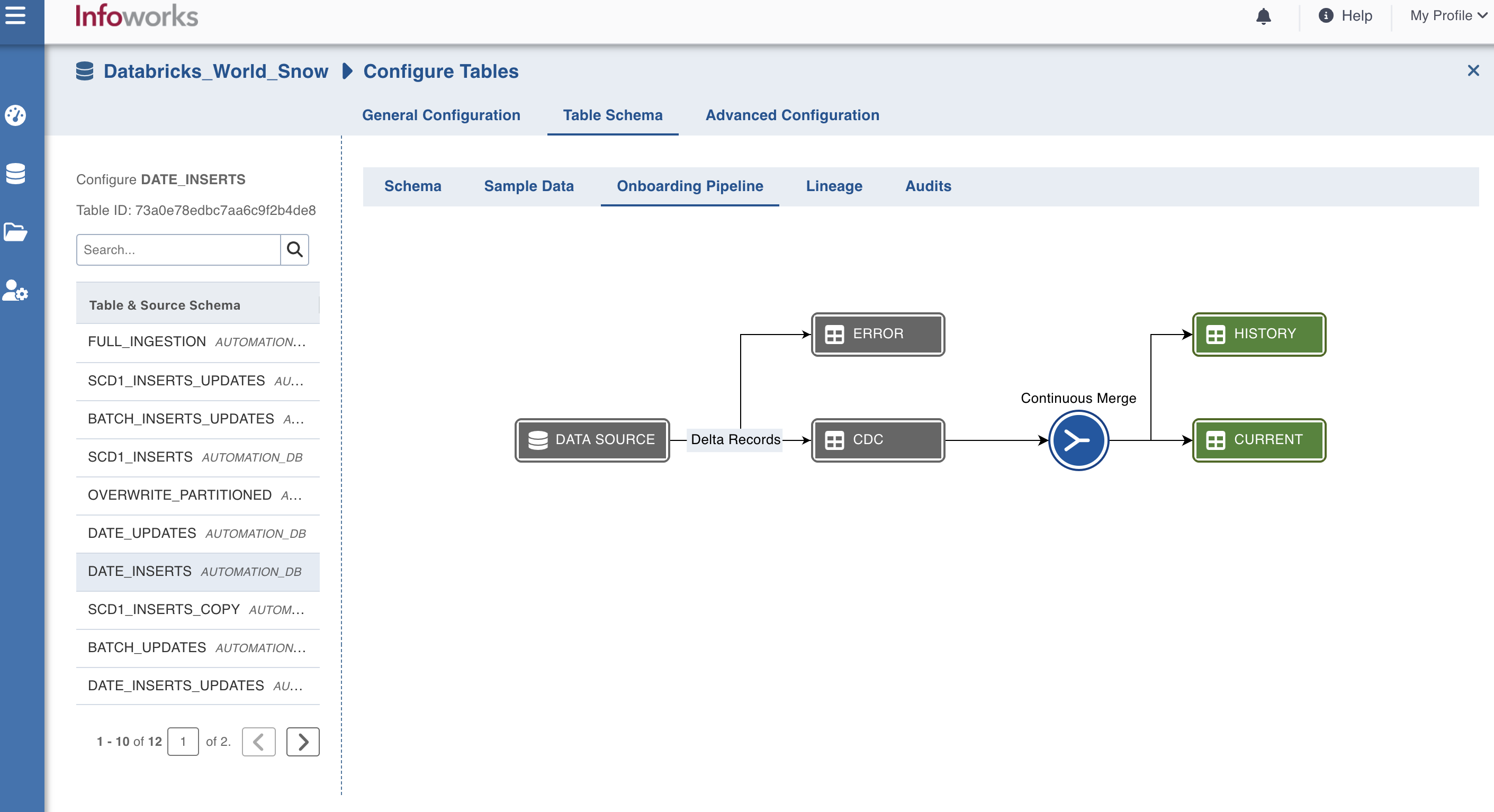
Onboarding Pipeline
The Data page includes a visual representation of all the Databricks metastore tables.
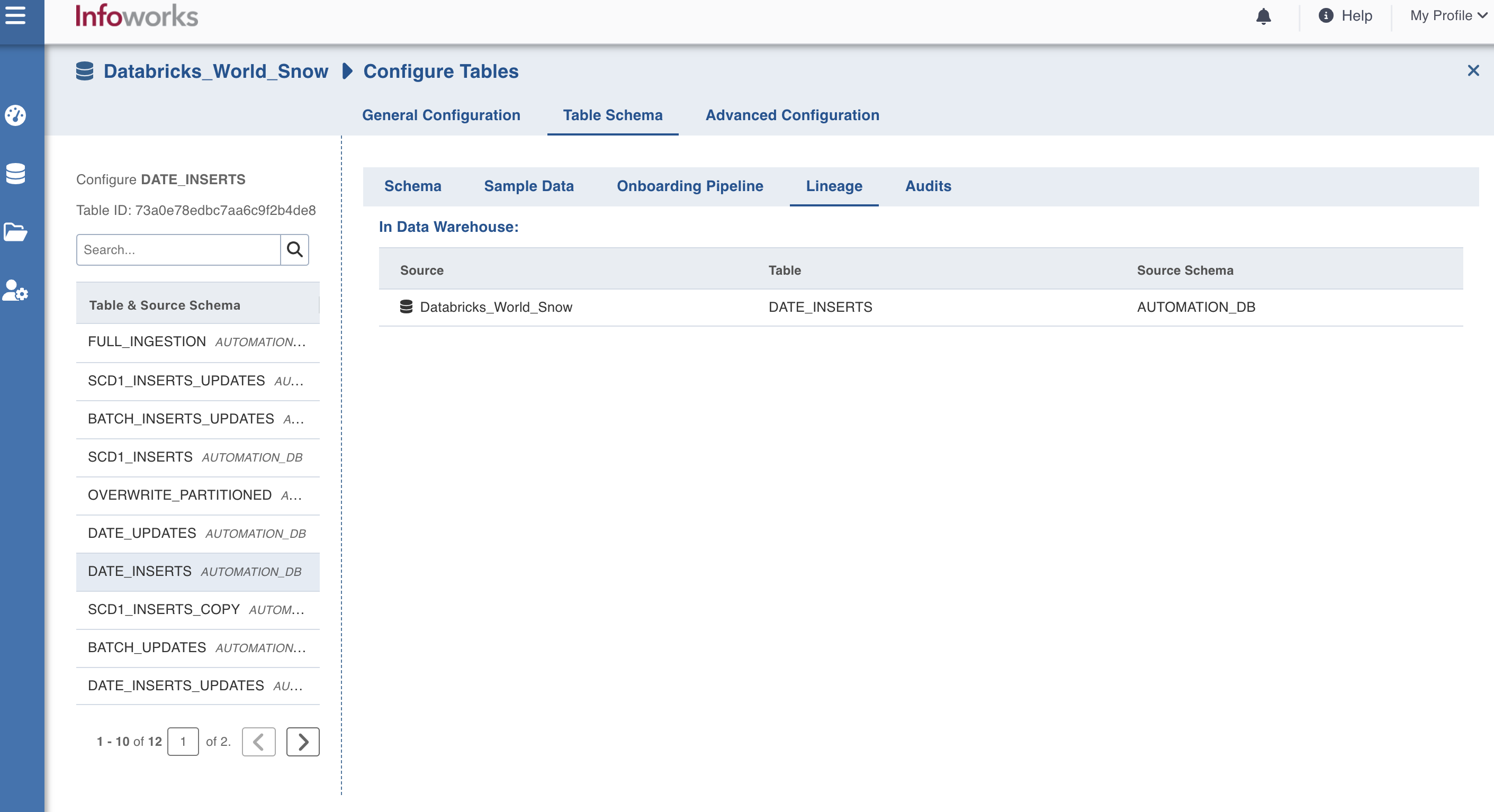
Viewing Data Lineage
The Lineage page displays all the instances where the data of the table is being used.
Viewing Source Audits
To view Source Audits, perform the following steps:
Click the Data Catalog menu and click View Source for the required source.
Click the Source Setup tab and scroll down to the Audits section. The audit logs for the source is displayed.
Alternatively, click the Tables tab > Configuration > Table Schema > Audits to view the audits section.
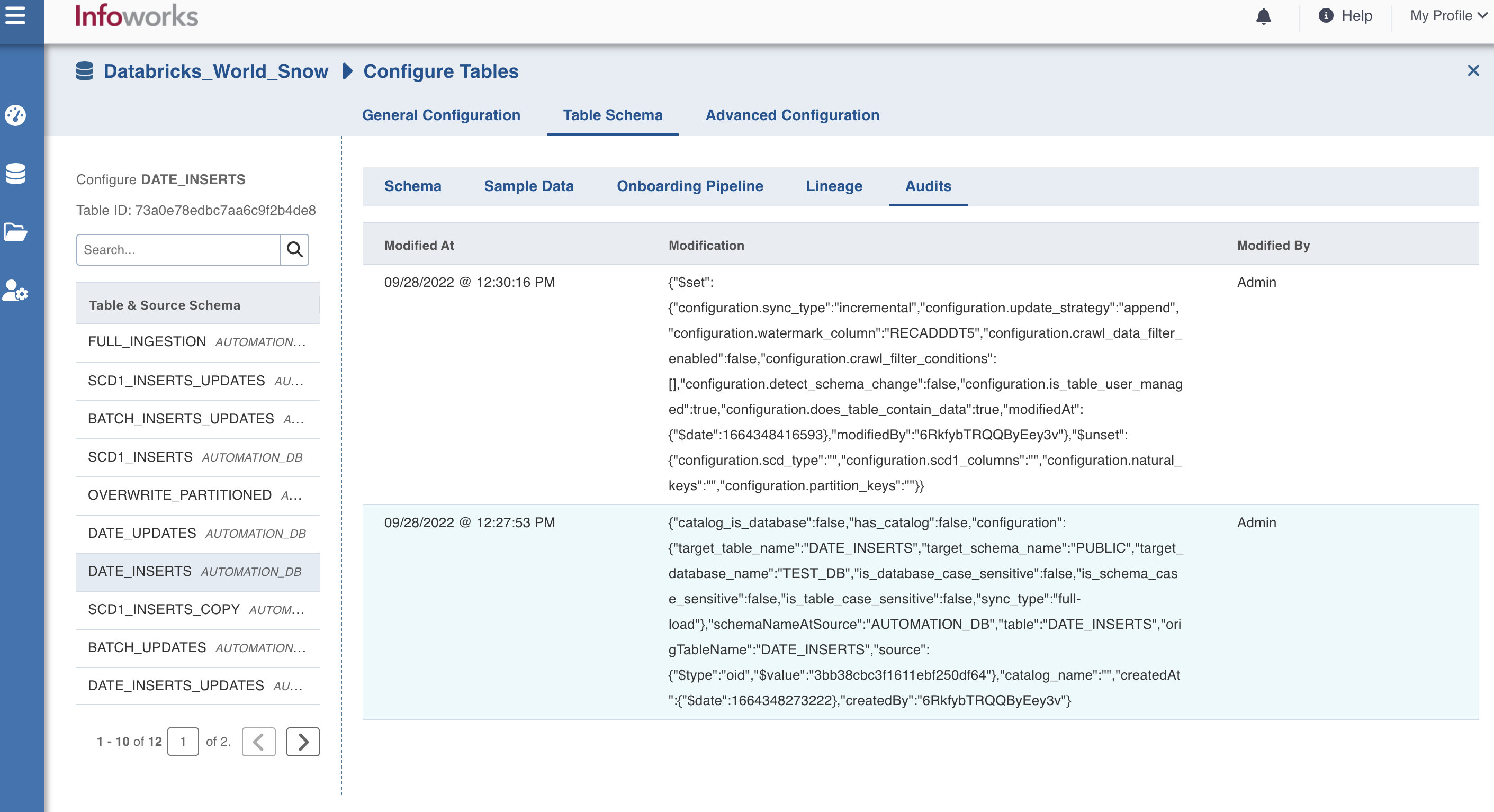
NOTE This screen displays only the modified properties. If a property was left unchanged during the iteration, it will not be displayed as an update, but the property will still be stored.
Audit Logs
In source audit logs, following are some operators:
$push - the operator displayed when an entity is added.
$pull - the operator displayed when an entity is deleted.
In table audit logs, when updating column details, following logs are displayed:
columns.<columnIndexInTable>.<key>:<UpdatedValue>- indicates single column update.columns:[<list of all the columns with details>]- indicates bulk column update.
Advanced Configurations
Following are the steps to set advanced configuration for a table:
Click the Data Catalog menu and click Ingest for the required source.
NOTE For an already ingested table, click View Source, click the Tables tab, click Configure for the required table, and click the Advanced Configurations tab.
Click the Configure Tables tab, click the Advanced Configurations tab, and click Add Configuration.
Enter key, value, and description. You can also select the configuration from the list displayed.
Partitioning of Temporary Storage
This feature is not being used in 5.2 pilot release.
Subscribers
You can add subscribers to be notified for the ingestion at the table level.
Click Add Subscriber, and enter the following fields:
Emails: The email ID of the subscriber.
Notify Via: The means of notification. Available options are Email and Slack.
Notify For: The jobs for which subscribers must be notified.
Configuring a Table with CDW Onboarding
With the source metadata in the catalog, you can now configure the table for CDC and incremental synchronization. There are two types of Cloud Data Warehouse: Snowflake and BigQuery. Click the Configuration link for the desired table.
General Configurations (Snowflake)
In the General Configurations tab, provide the following Ingestion Configuration details:
Field | Description |
|---|---|
Ingest Type | The type of synchronization for the table. The options include full refresh and incremental. |
Natural Keys | The combination of keys to uniquely identify the row. This field is mandatory in incremental ingestion tables. It helps in identifying and merging incremental data with the already existing data on target. NOTE At least one of the columns in the natural key must have a non-null value for Infoworks merge to work. |
Incremental Mode | The option to indicate if the incremental data must be appended or merged to the base table. This field is displayed only for incremental ingestion. The options include append and merge. |
SCD Type | A dimension that stores and manages both current and historical data over time in a data warehouse. The options include SCD1 and SCD2. NOTE This field is displayed only when the ingestion is Incremental and the incremental mode is Merge. |
Watermark Column | The watermark column to identify the incremental records. NOTE This field is displayed only for incremental ingestion. |
Enable Watermark Offset | For Timestamp and Date watermark columns, this option enables an additional offset (decrement) to the starting point for ingested data. Records created or modified within the offset time period are included in the next incremental ingestion job. NOTE Timestamp watermark column has three options: Days, Hours and Minutes, and the Date watermark column has Days option. In both the cases, the options will be decremented from the starting point. |
Ingest subset of data | The option to configure filter conditions to ingest a subset of data. This option is available for all the RDBMS and Generic JDBC sources. For more details, see Filter Query for RDBMS Sources |
Optimization Configuration | |
Split By Column | The column used to crawl the table in parallel with multiple connections to the database. Split-by column can be an existing column in the data. Any column for which minimum and maximum values can be computed, can be a split-by key. Select the Create Derived Split Column option and provide the Derived Split Column Function to derive a column from the Split By column. This option is enabled only if the Split By column datatype is date or timestamp. The data will be split based on the derived value. |
Create Derived Split Column | Select the Create Derived Split Column option and provide the Derived Split Column Function to derive from the Split By column. This option is enabled only if the Split By column data type is integer or timestamp. The data will be split based on the derived value. mod: For every float, integer, or long value, the mod function is performed on the number of connections that are available on the database and based on the mod value the corresponding database is updated. The mod function is first applied to the column and after getting the output the split gets applied and the data is evenly distributed. The mod function is applied on each row level and all the connections run parallelly until the end of the job. |
Target Configuration | |
Database Name | Database name of the Snowflake target. |
Table Name | Table name of the Snowflake Target. |
Schema Name | The schema name of the Snowflake Target. |
Generate History View | Select this option to preserve data in the History table. After each CDC, the data will be appended to the history table. |
Is user managed? | When enabled, user managed table behavior works as an external table to Infoworks. The table will not be created/dropped or managed by Infoworks. |
General Configurations (BigQuery)
Field | Description |
|---|---|
Ingest Type | The type of synchronization for the table. The options include full refresh and incremental. |
Natural Keys | The combination of keys to uniquely identify the row. This field is mandatory in incremental ingestion tables. It helps in identifying and merging incremental data with the already existing data on target. NOTE At least one of the columns in the natural key must have a non-null value for Infoworks merge to work. |
Incremental Mode | The option to indicate if the incremental data must be appended or merged to the base table. This field is displayed only for incremental ingestion. The options include append and merge. |
SCD Type | A dimension that stores and manages both current and historical data over time in a data warehouse. The options include SCD1 and SCD2. NOTE This field is displayed only when the ingestion is Incremental and the incremental mode is Merge. |
Watermark Column | The watermark column to identify the incremental records. NOTE This field is displayed only for incremental ingestion. |
Enable Watermark Offset | For Timestamp and Date watermark columns, this option enables an additional offset (decrement) to the starting point for ingested data. Records created or modified within the offset time period are included in the next incremental ingestion job. NOTE Timestamp watermark column has three options: Days, Hours and Minutes, and the Date watermark column has Days option. In both the cases, the options will be decremented from the starting point. |
Ingest subset of data | The option to configure filter conditions to ingest a subset of data. This option is available for all the RDBMS and Generic JDBC sources. For more details, see Filter Query for RDBMS Sources |
Optimization Configuration | |
Split By Column | The column used to crawl the table in parallel with multiple connections to the database. Split-by column can be an existing column in the data. Any column for which minimum and maximum values can be computed, can be a split-by key. Select the Create Derived Split Column option and provide the Derived Split Column Function to derive a column from the Split By column. This option is enabled only if the Split By column datatype is date or timestamp. The data will be split based on the derived value. |
Create Derived Split Column | Select the Create Derived Split Column option and provide the Derived Split Column Function to derive from the Split By column. This option is enabled only if the Split By column data type is integer or timestamp. The data will be split based on the derived value. mod: For every float, integer, or long value, the mod function is performed on the number of connections that are available on the database and based on the mod value the corresponding database is updated. The mod function is first applied to the column and after getting the output the split gets applied and the data is evenly distributed. The mod function is applied on each row level and all the connections run parallelly until the end of the job. |
Target Configuration | |
Onboarding Option | Select the target onboarding option. The options available are direct and indirect. |
Dataset Name | Dataset name of the BigQuery target. |
Table Name | Table name of the BigQuery Target. |
Partition Type | The type of partition for the BigQuery table. By default, the Partition Type is set to None. The available options are Date Column, Timestamp Column, Integer Column. BigQuery Load Time option is available when the Onboarding Option is set to Indirect. NOTE For other partition types, user can choose to create the table with desired partitions in BigQuery. |
Partition Column | The column to be used to partition tables in target. The column needs to be of Date data type. |
Partition Time Interval | This field is visible when the Partition type is Date Column, Timestamp Column, or NOTE For _Date column**, the available options are Day, Month, and Year. For Timestamp column, the available options are Hour, Day, Month, and _Year. For _BigQuery Load Time**, the available options are Hour, Day, Month, and Year. |
Clustering Columns | The columns to be used for clustering. You can select up to 4 columns. |
Is user managed? | When enabled, user managed table behavior works as an external table to Infoworks. The table will not be created/dropped or managed by Infoworks. |
Generate History View | Select this option to preserve data in the History table. After each CDC, the data will be appended to the history table. |
NOTE
If the combination of schema name, database name and table name are same across different tables in the same environment, an error appears showing the combination of the three is conflicting with another table.
For Snowflake, we check the combination of table name, schema name and database name
For BigQuery, we check the combination of dataset name and table name.
For all other environments, we check combination of schema name and table name.