Introduction
Infoworks’ BigQuery data environment enables onboarding data directly into BigQuery and transforming data in BigQuery. Workloads may be orchestrated using Infoworks’ orchestration capabilities and monitored using the operational dashboards. This section will help you configure an Infoworks data environment to work with BigQuery.
Procedure
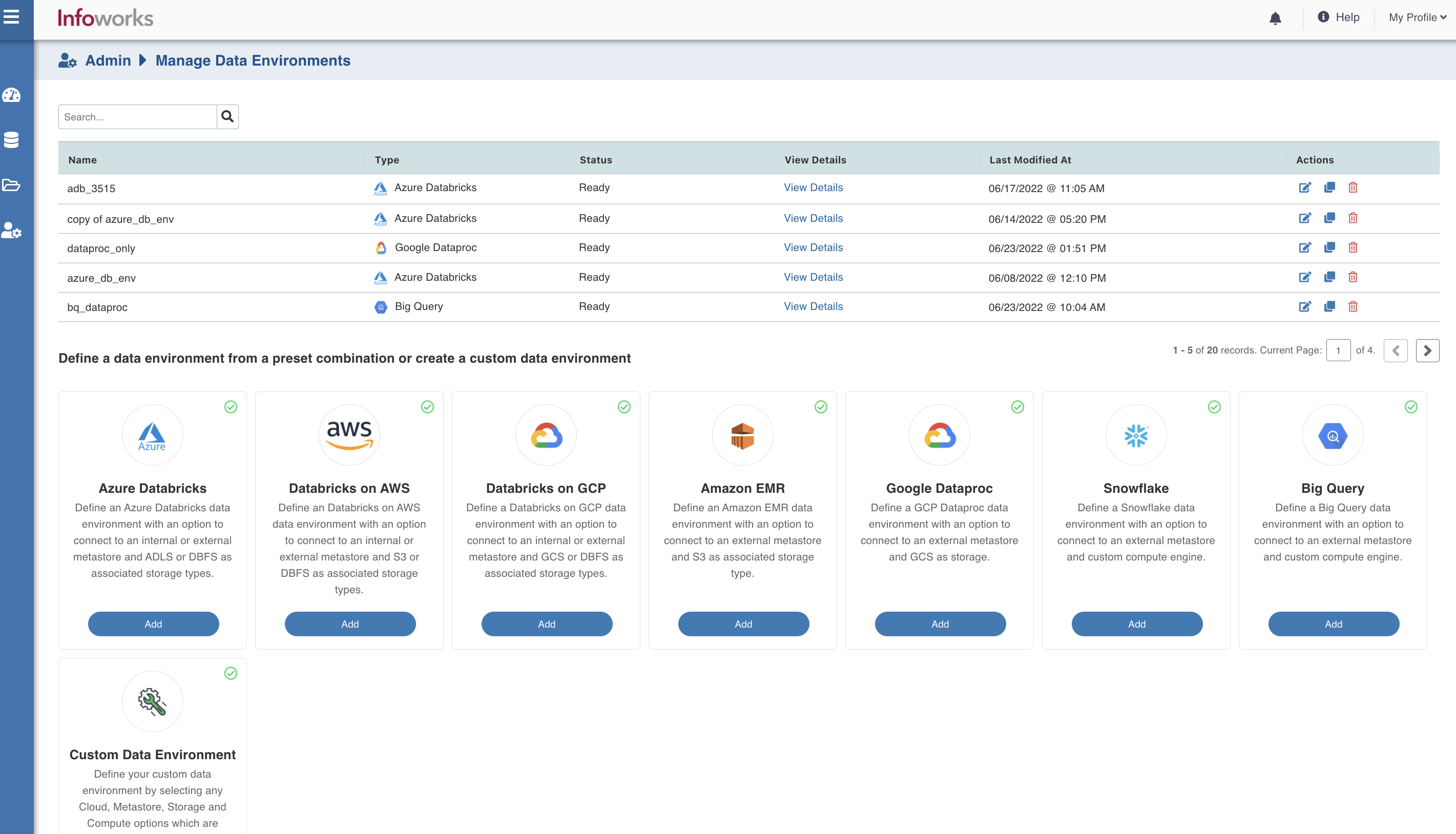
To configure and connect to the required BigQuery instance, navigate to Admin > Manage Data Environments, and then click Add button under the BigQuery option.
The following window appears:
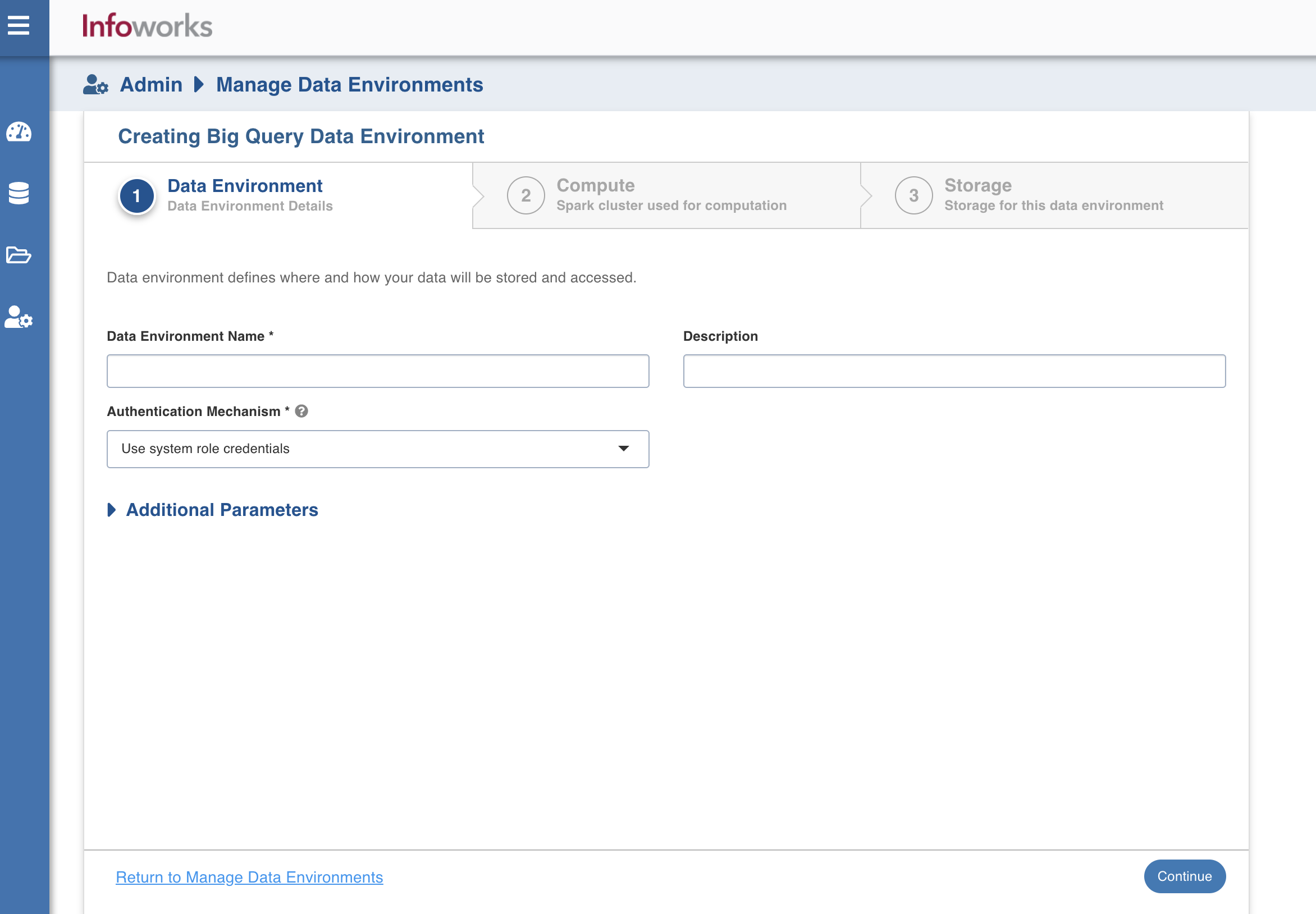
There are three tabs to be configured as follows:
Data Environment
To onboard data directly to BigQuery, you should configure a BigQuery environment that includes cloud storage and one or more Spark computes. Cloud storage is used temporarily to stage data during ingestion and to store sample data. To configure the data environment details, enter values in the following fields. This defines the environmental parameters, to allow Infoworks to be configured to the required BigQuery instance:
| Field | Description | Details |
|---|---|---|
| Data Environment Name | Data environment defines where and how your data will be stored and accessed. Data environment name must help the user to identify the environment being configured. | User-defined. Provide a meaningful name for the data environment being configured. |
| Description | Description for the environment being configured. | User-defined. Provide required description for the environment being configured. |
| Authentication Mechanism | Specifies the authentication mechanism using which the security information is stored. Includes the following authentication mechanisms:
| The System role credentials option uses the default credentials of the instance to identify and authorize the application. The Service account credentials uses the IAM Service Account to identify and authorize the application. |
| Service Credentials | Option to select the service credential which authenticates calls to Google Cloud APIs or other non-Google APIs. | Radio Button. Available options are Upload File or Enter File Location. |
| Section: Additional Parameters | Click the Add button to provide the parameters in key-value pair. | Provide additional parameters required to connect to BigQuery. It is non mandatory. |
After entering all the required values, click Continue to move to the Compute tab.
Compute
A Compute template is the infrastructure used to execute a job. This compute infrastructure requires access to the metastore and storage that needs to be processed. To configure the compute details, enter values in the following fields. This defines the compute template parameters to allow Infoworks to be configured to the required BigQuery instance.
You can select one of the clusters as the default cluster for running the jobs. However, this can be overwritten at individual job level.
Infoworks supports creating multiple persistent clusters in a BigQuery environment, by clicking the Add button.
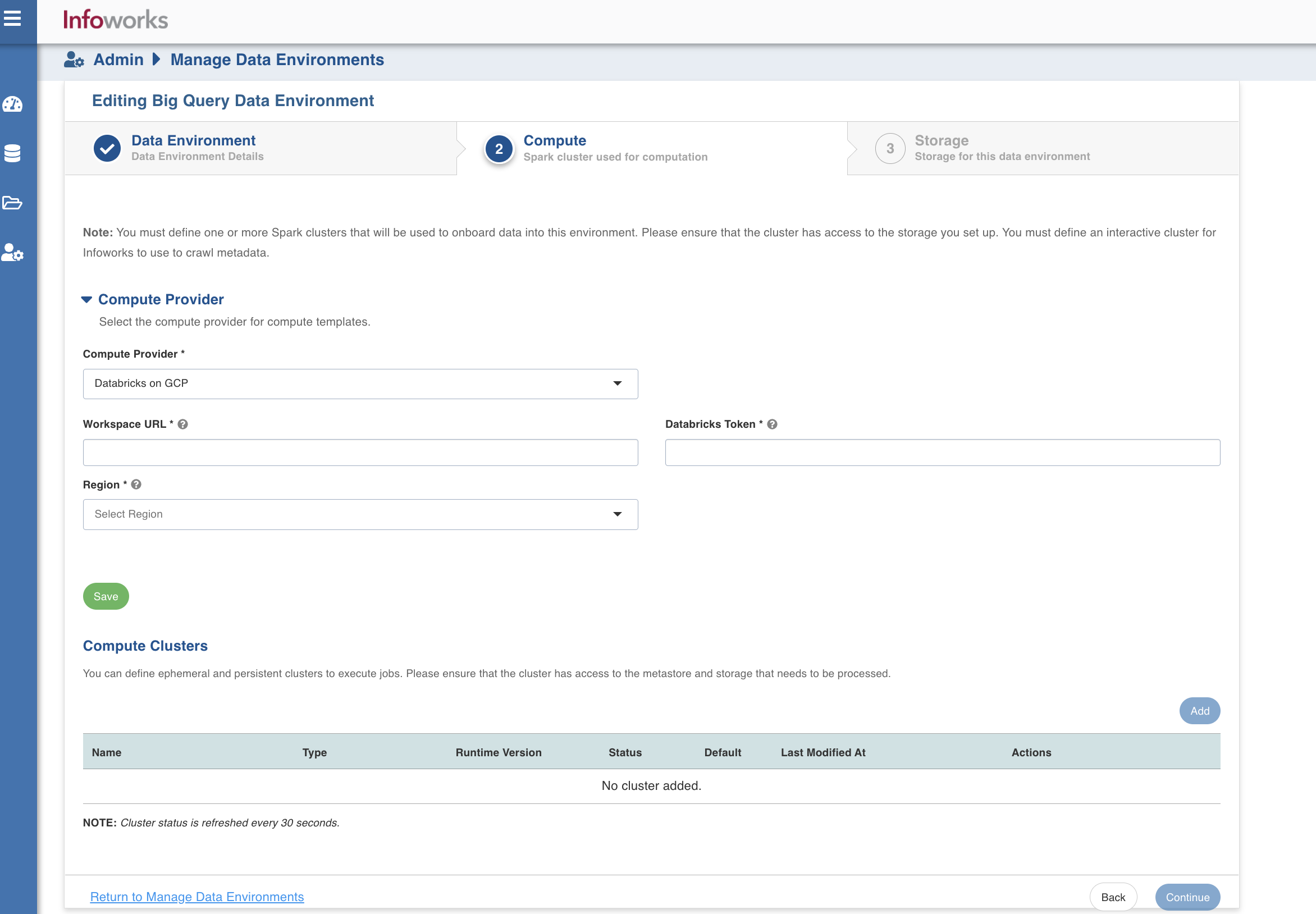
Enter the fields in the Compute section:
| Field | Description | Details |
|---|---|---|
| Compute Provider | ||
| Compute Provider | The type of compute provider required for creating compute templates | Choose from the available options: Google Dataproc and Databricks on GCP |
| Workspace Url | URL of the workspace that Infoworks must be attached to. | Provide the required workspace URL. |
| Databricks Token | Databricks access token of the user who uses Infoworks. | Provide the required Databricks token. |
| Region | Geographical location where you can host your resources. | Select the required region from the drop-down. |
| Compute Clusters | ||
| Cluster Type | The type of compute cluster that you want to launch. | Choose from the available options: Persistent or Ephemeral. Jobs can be submitted on both Ephemeral as well as Persistent clusters. |
| Name | Name required for the compute template that you want to use for the jobs. | User-defined. Provide a meaningful name for the compute template being configured. |
| Description | Description required for the compute template. | User-defined. Provide required description for the compute template being configured. |
| Custom Tags | Enter the key-value pairs that help you identify resources based on settings that are relevant to your organization. | Provide the required custom tags. |
| Runtime Version | Select the Runtime version of the compute cluster that is being used. | Select the Runtime version. If you are using Databricks on GCP, you can either select 7.3 or 9.1 from the drop-down as per your requirement. If you are using Google Dataproc, select 2.0 from the dropdown. |
| Region | Geographical location where you can host your resources. | Provide the required region. For example: East US. |
| Workspace URL | URL of the workspace that Infoworks must be attached to. | Provide the required workspace URL. |
| Databricks Token | Databricks access token of the user who uses Infoworks. | Provide the required Databricks token. |
| Allow single node instance | Option to run single node clusters. | A single node cluster is a cluster consisting of an apache spark driver and no spark workers. |
| Use Instance Pool | Option to use a set of idle instances which optimizes cluster start and auto-scaling times. | If Use Instance pool check box is checked, provide the ID of the created instance pool in the additional field that appears. |
| Worker Type | Worker type configured in the edge node. | This field appears only if Use Instance pool check box is unchecked. Provide the required worker type. For example: Standard_L4 |
| Driver Type | Driver type configured in the edge node. | This field appears only if Use Instance pool check box is unchecked. Provide the required worker type. For example: Standard_L4 |
| Max Allowed Worker Nodes | Maximum number of worker instances allowed. | Provide the maximum allowed limit of worker instances. |
| Enable Autoscale | Option for the instances in the pool to dynamically acquire additional disk space when they are running low on disk space. | Select this option to enable autoscaling. |
| Min Workers Node | Minimum number of workers that workspace maintains. | This field appears only if Enable Autoscale check box is checked. |
| Max Workers Node | Maximum number of workers that workspace maintains. | This field appears only if Enable Autoscale check box is checked. This must be greater than or equal to Default Min Worker value. |
| Number of Worker Nodes | Number of workers configured for availability. | This field appears only if Enable Autoscale check box is unchecked. |
| Terminate after minutes of inactivity | Number of minutes after inactivity which the pool maintains before being terminated. | Provide the minimum number of minutes to be maintained before termination. |
Storage
To configure the storage details, enter values in the following fields. This defines the storage parameters, to allow Infoworks to be configured to the required BigQuery instance. After configuring a storage, you can choose to make it default storage for all jobs. However, this can be overwritten at individual job level.
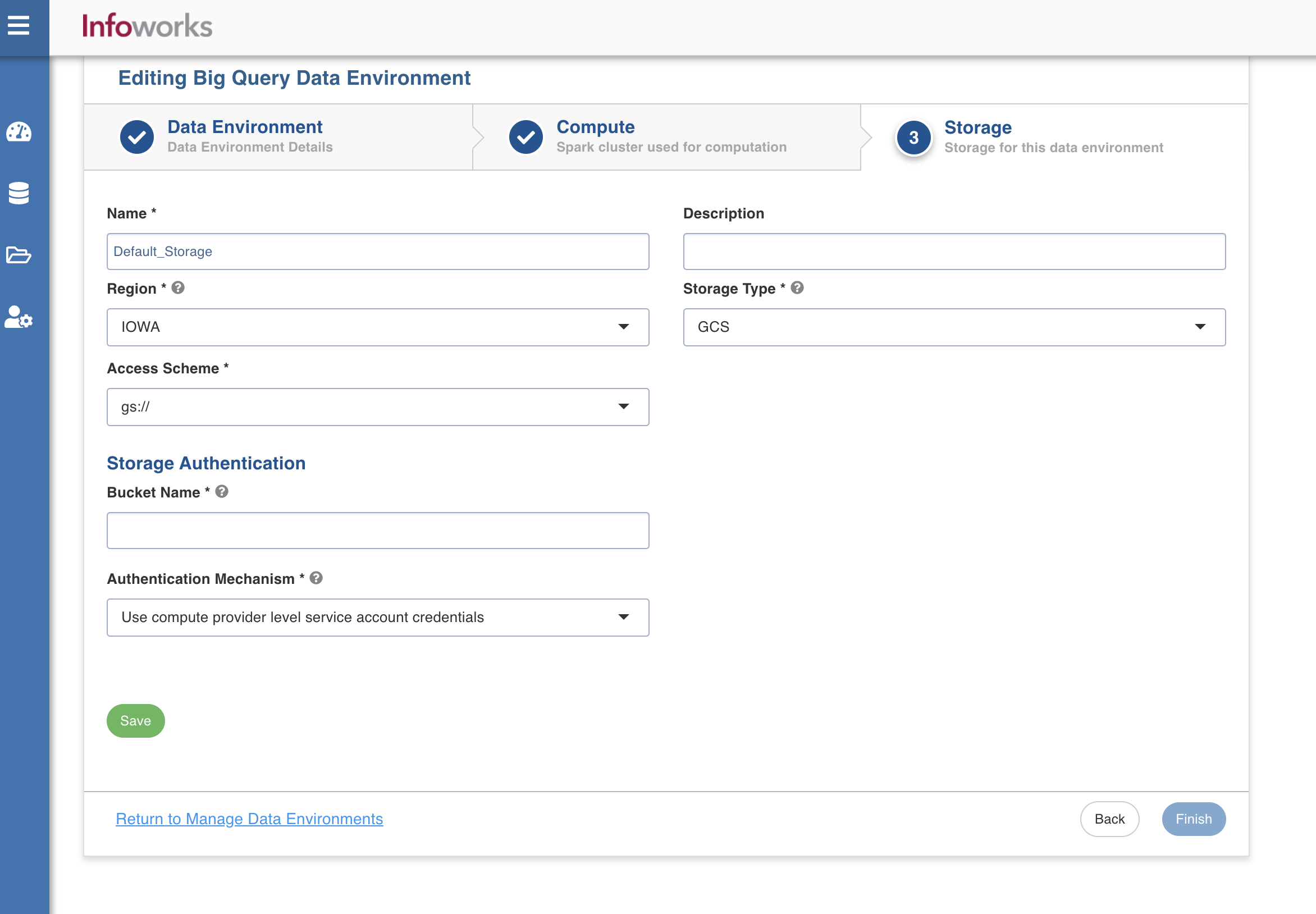
Enter the following fields under the Storage section:
| Field | Description | Details |
|---|---|---|
| Name | Storage name must help the user to identify the storage credentials being configured. | User-defined. Provide a meaningful name for the storage set up being configured. |
| Description | Type of storage system where all the artifacts will be stored. This depends on the type of cloud/platform provider you choose in the Compute tab. | Select the required storage type from the drop-down menu. The available option is GCS. |
| Access Scheme | Scheme used to access GCS. | This field appears only when the storage type is selected as GCS. |
| Storage Authentication | ||
| Bucket Name | Buckets are the basic containers that hold, organise, and control access to your data. | Provide the storage bucket key. Do not use gs:// for storage bucket. |
| Authentication Mechanism | Specifies the authentication mechanism using which the security information is stored. Includes the following authentication mechanisms:
| The System role credentials option uses the default credentials of the instance to identify and authorize the application. The Service account credentials uses the IAM Service Account to identify and authorize the application. |
| Service Credentials | Option to select the service credential which authenticate calls to Google Cloud APIs or other non-Google APIs. | This field appears only when the Authentication mechanism is selected as Use service account credentials. Available options are Upload File or Enter File Location. |
- For indirect method of ingestion in BigQuery environment, the GCS bucket used for staging and the BigQuery target should be in the same project. If the two are in different GCP projects, the ingestion will fail.
- Different service accounts can be used for BigQuery and GCS bucket, but they should belong to the same GCP project.
- Ingestion job works fine if BigQuery and GCS are in the same project and the cluster created is in some other GCP project.
After entering all the required values, click Save. Click Finish to view and access the list of all the environments configured. Edit, Clone, and Delete actions are available on the UI, corresponding to every configured environment.