The SQL Import feature is used to automatically build reliable, scalable and efficient pipelines. The feature is designed to make it easier to build large scale, real-time data pipelines by standardizing how you modify and align the ingested sources and tables.
You can create complex pipelines with just a few clicks by periodically executing an SQL query and creating an output record for each table/row in the result set.
Following are the steps to build an ETL pipeline:
- Click the Domains menu.
- Click the required domain in which you want to create an ETL pipeline.
- Click the Pipelines icon in the side bar.
- Click New Pipeline, enter the required values and click Save.
- Click the newly created pipeline to open the blank Design.
- Click the Settings icon.
- On the Settings page, scroll down to the SQL Import section.
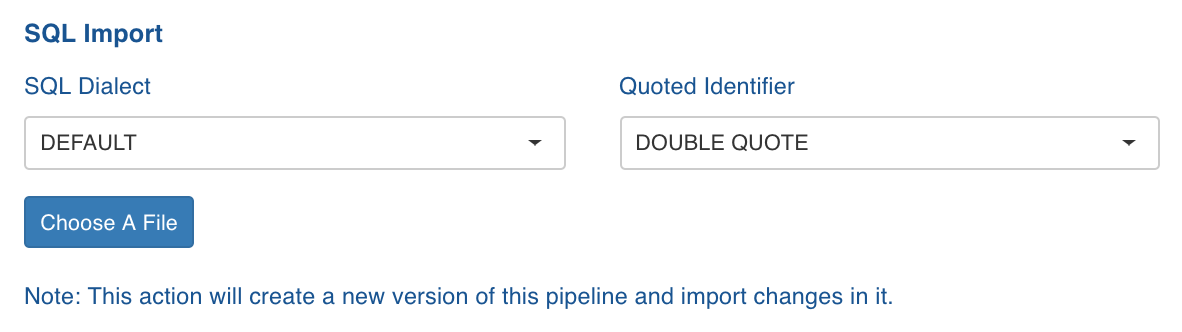
- Select the following:
- SQL Dialect: The SQL compatibility mode based on query type. For example, select Oracle to import Oracle SQL queries.
- Quoted Identifier: the syntax for quoting identifiers in SQL statements.
- Click Choose A File and select the required SQL file. Following is an example of SQL file content with the Filter criteria, without any schema specified.
xxxxxxxxxxSELECT shipvia FROM ORDERS WHERE 2 AND orderid is not nullFollowing shows the sample SQL file content with the schema name (SALES_DB2).
xxxxxxxxxxSELECT DISTINCT count(shipvia) as count_shipvia, shipvia + 10 FROM SALES_DB2.ORDERS- In the Table in Data Lake drop-down list, select the table that has the same columns as the ones in the uploaded file.
- At this point, if you want to import a different SQL file, click Return to Pipeline Settings. To proceed with the same SQL file, click Next: Import Workload.
- After the successful import of the SQL file, return to pipeline editor page, edit the target configuration, and build the pipeline.
- Usage of the keyword QUALIFY is not supported.
- SQL queries that can not be parsed using Calcite parser are not supported.
- Insert into table values are not supported in pipeline SQL import.
- Following queries are supported by Calcite but not by SQL Import:
| Query type | Example |
|---|---|
| Nested Select in column list. | Select a, (select b from table1) from table2 |
| Subqueries in having clause | Select a, sum(b) from table1 group by aHaving sum(b) > (select count(*) from table2) |
| Correlated-subqueries in JOIN condition | Select * from tb1 inner join tb2 on tb1.a = tb2.a and tb1.c = ( Select max(c) from tb2 where q1=q2)) |
Was this page helpful?