The Aggregate node allows you to derive new columns by applying aggregate functions such as count, distinct count, sum, distinct sum, min, max, average, distinct average, and variance over a group of values.
Following are the steps to apply the Aggregate node in a pipeline:
- Drag and drop the Aggregate node from the Transformations section to the pipeline editor page.
- Connect the source node to the Aggregate node.
- Double-click the Aggregate node. The properties page is displayed.
- Click Add Group By, select the Group By Column for which the derived data is to be grouped by, and click Save.
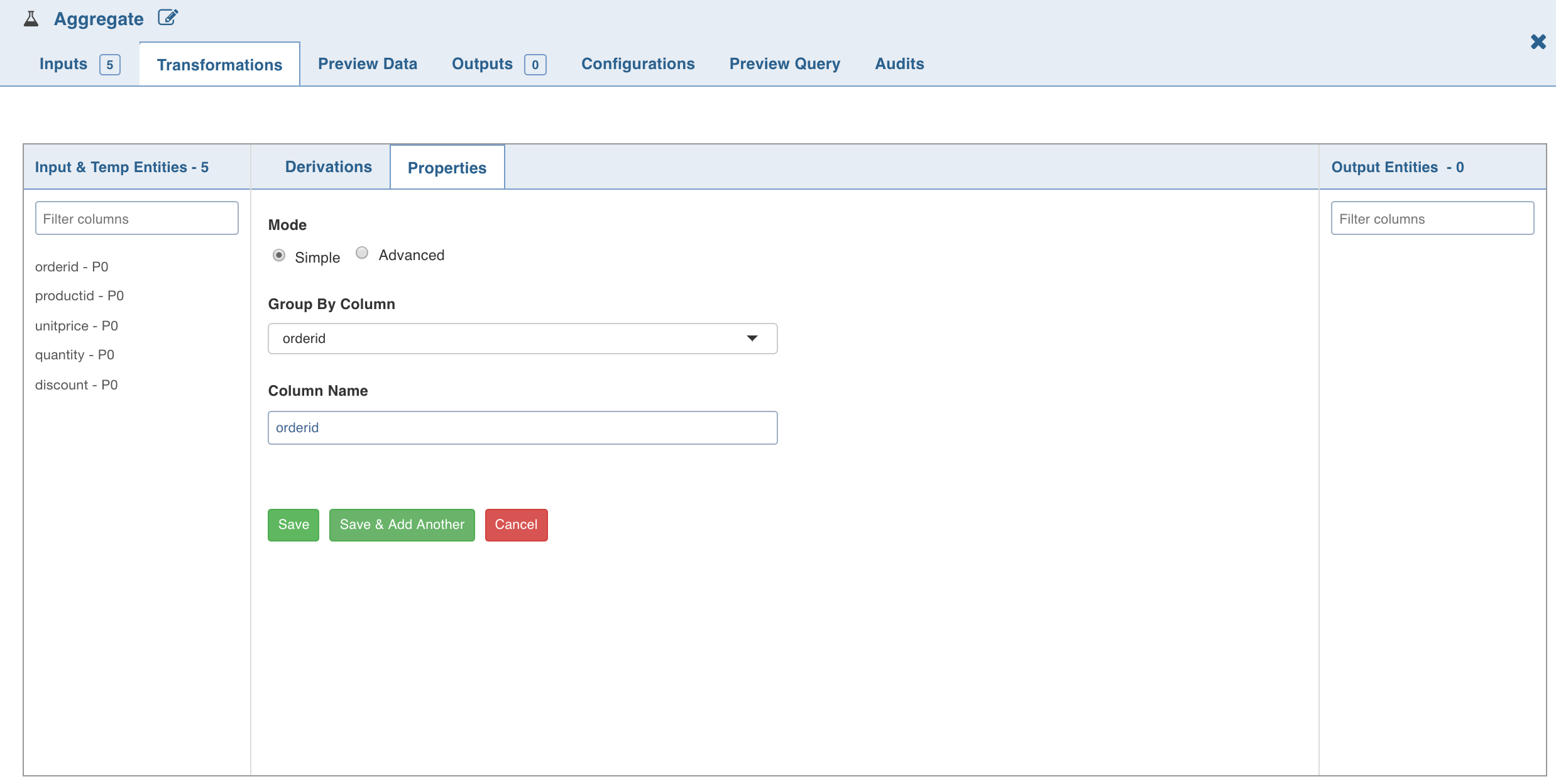
5. To set the expression, select the Advanced mode and enter the expression and click Save.
- Click Add Aggregate and enter the following details:
| Field | Description |
|---|---|
| Column Name | The name for the output column with aggregated data. |
| From Column | The column on which the aggregate function is to be performed. |
| Function | The aggregate function to be applied on the column. The options include Count, Distinct Count, Sum, Distinct Sum, Avg, Distinct Avg, Min, Max, and Variance. |
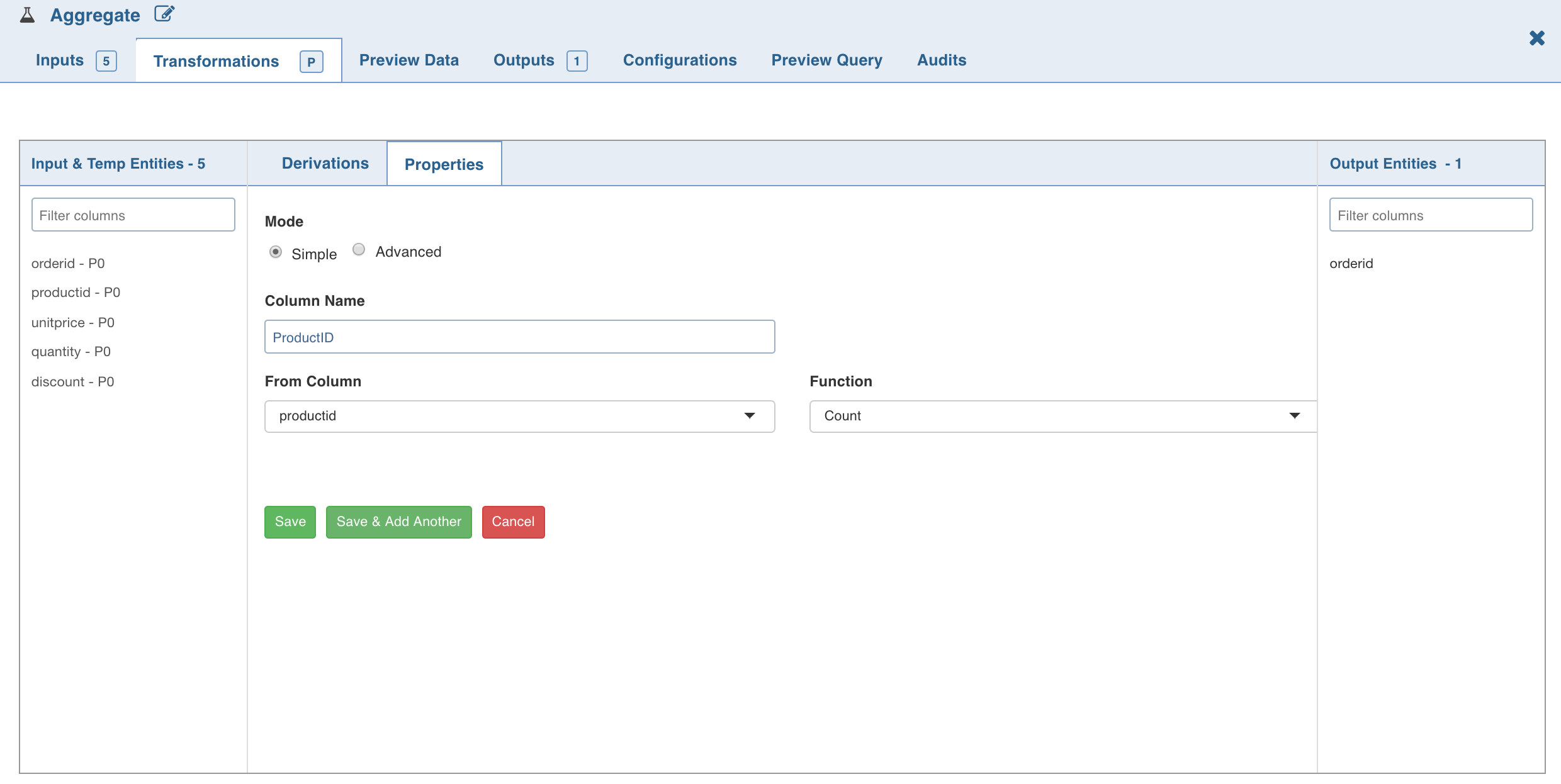
- To set the Aggregate expression, select Advanced mode and enter the expression and click Save.
- The aggregated data is fetched based on the columns and functions used. All group by and derived columns are added in the metadata section.
- For details on derivations, see Derivations.
DISTINCT(col1, col2)is not supported by Snowflake and BigQuery: The pipeline build fails if this SQL is imported in Snowflake or BigQuery execution engine environments.
Post Processing Configuration
For details, see Configurations-Post Processing.
Was this page helpful?