The Union node allows you to combine the data from two or more tables (nodes).
NOTE Hive versions prior to 1.2.0 supports only UNION ALL and not UNION DISTINCT.
Following are the steps to apply the Union node in a pipeline:
Drag and drop the Union node from the Transformations section to the pipeline editor page.
Connect the source node to the Union node.
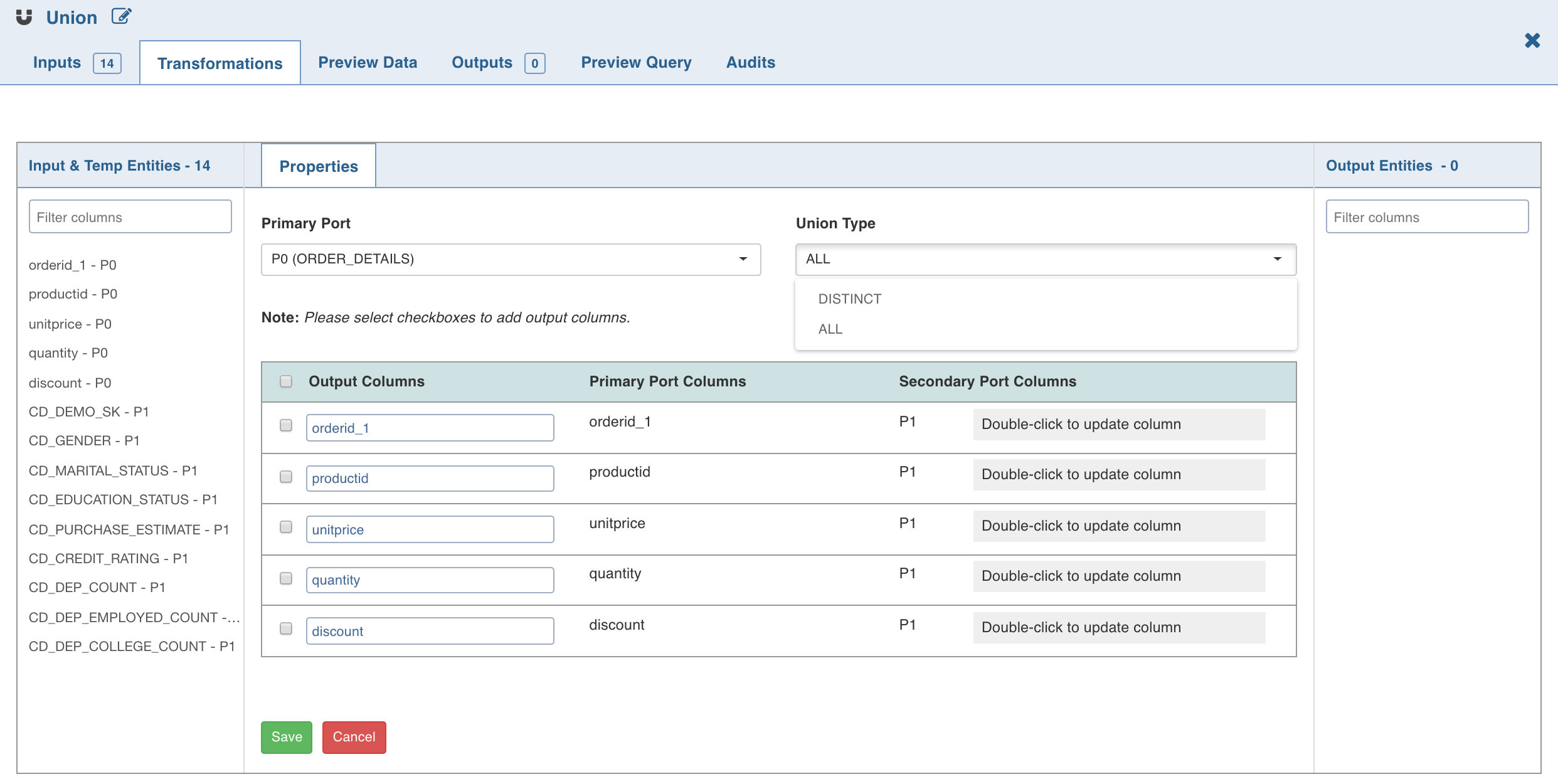
Double-click the Union node. The properties page is displayed.
Click Edit Union to add union data. The tables (nodes) involved in the union condition are displayed along with column name section.
Select the following details and click Save:
Primary Port to which the tables will be combined.
NOTE Columns of other tables can be mapped to the primary table. You cannot change the order of primary table columns. All the column fields in the other table sections can be edited depending on which columns of that table and the primary table should match. You can change the primary table using the primary table drop-down.
Type: The ALL option adds all the rows to the union node. DISTINCT adds only the distinct rows to the union node.
If required, rename the columns under Column Name. The Column Name includes the columns of the Primary Table and only these names can be edited.
Map/rearrange the column order of the other tables (based on name) using edit. The edit feature is not available for primary tables.
Use the checkboxes on the left of primary table column names to add or remove the columns in the union node.
NOTE When Using Impala as Execution Engine, UNION DISTINCT is not supported.
Known Issue
The changes made to the upstream nodes such as Aggregate and Distinct nodes, connecting to the Union node may not propagate into the Union node. Workaround: To have the changes propagated in the Union node, click Edit Union and remap it.