This chapter describes the ingestion functionalities supported by Infoworks.
Ingestion is the first step to perform data analytics on Hadoop. Ingestion brings data from various sources such as RDBMS, delimited files, unstructured files, etc onto Hadoop.
Following are the types of ingestion supported based on the databases:
- RDBMS Ingestion supports the following database types: Teradata, Oracle, MySQL, Maria DB, SQL Server, DB2, Netezza, SAP Hana, Hive, SybaseIq, Apache Ignite, Vertica.
- No SQL supports MapR-DB Ingestion.
- CRM supports SalesForce Ingestion.
- File Ingestion includes the following types:
- Structured File Ingestion - Delimited File Ingestion, Fixed Width Ingestion, Mainframe Data File Ingestion
- JSON Ingestion
- XML Ingestion
- Unstructured File Ingestion
Following are the two main prerequisites for ingestion:
Creating Source
NOTE: Only an admin can create a source.
- Login to Infoworks DF.
- Navigate to Admin > Sources > New Source.
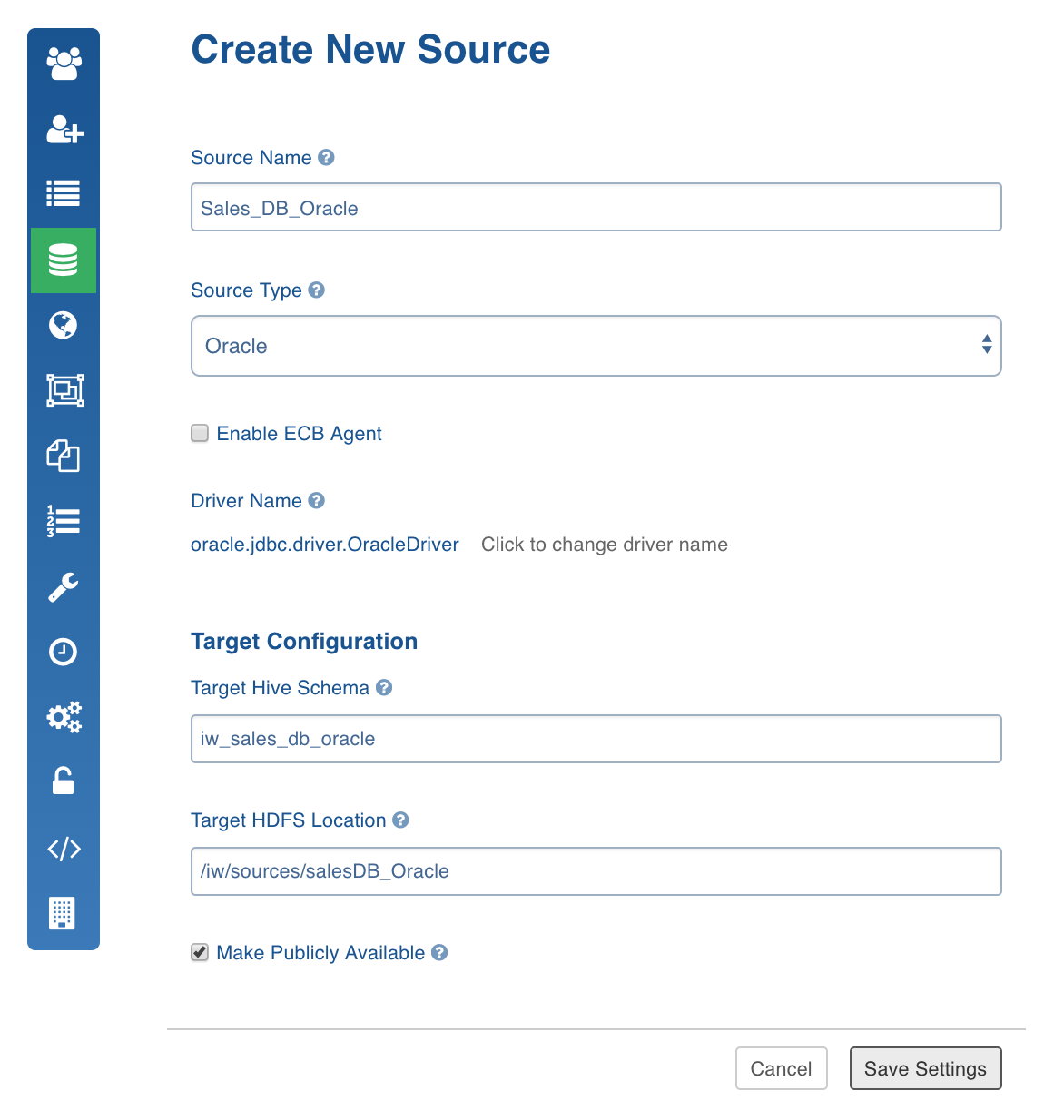
In the Create New Source page, enter the following details:
- Source Name: Name of source on the Infoworks platform.
- Source Type: The Files source type includes Structured Files (CSV, TSV), JSON Files, XML Files and Unstructured Files. The RDBMS source type includes Teradata, MySQL, MariaDB, Oracle, SQL Server, DB2, Netezza, SAP Hana, Hive, SybaseIq, Apache Ignite,Redshift and Vertica. The No SQL source type includes MapR DB. The CRM source type includes salesforce.com. For list of data types supported by these source types, see the Data Types section.
- Driver Name: Once you select the Source Type, the JDBC driver name for the database will be displayed. You can also edit the driver name.
- Target Hive Schema: Hive schema name created by Hadoop admin.
- Target HDFS Location: HDFS path on Hadoop cluster, created by Hadoop admin.
- Click Save Settings.
Installing External Client Drivers
To install external client drivers like Netezza, SAP HANA, and Teradata, see External Client Drivers.
Ingestion Jobs
Following are the types of ingestion jobs you can perform to achieve specific types of ingestions:
| Job Type | Description |
|---|---|
| source_test_connection | Test connection job for all RDBMS. |
| source_fetch_metadata | Metadata crawl for RDBMS. |
| source_structured_fetch_metadata | Metadata crawl for file based ingestion. |
| source_crawl | Initialize and ingest for RDBMS over JDBC. |
| source_crawl_tpt | Initialize and ingest for teradata source while using TPT. |
| source_crawl_stage_tpt | Stage data job for teradata while using TPT when crawling for the first time. |
| source_crawl_process_tpt | Processing job for teradata while using TPT when crawling for the first time. |
| source_crawl_chunk_load | Segmented load for RDBMS. |
| source_stage_tpt | Stage data task for incremental load. |
| source_cdc | CDC job for RDBMS. |
| source_cdc_tpt | CDC job for teradata while using TPT. |
| source_merge | Merge job for RDBMS. |
| source_merge_tpt | Merge job for teradata while using TPT. |
| source_switch | Commit to the data after merge. |
| source_cdc_merge | CDC and merge job ingest now for RDBMS. |
| source_stage_cdc_merge_tpt | Ingest now for teradata sources while using TPT. |
| source_unstructured_crawl | Initialize and ingest now for unstructured files. |
| source_unstructured_cdc | Ingest now for unstructured files. |
| source_structured_crawl | Initialize and ingest now for CSV and fixed-width ingestion. |
| source_structured_cdc_merge | Ingest now for CSV and fixed-width ingestion. |
| source_structured_cdc | CDC job for CSV and fixed-width ingestion. |
| source_structured_merge | Merge job for CSV and fixed-width ingestion. |
| source_semistructured_crawl | Initialize and ingest now job for JSON and XML ingestion. |
| source_semistructured_cdc_merge | Ingest now job for JSON and XML. |
| source_semistructured_cdc | CDC job for JSON and XML. |
| source_semistructured_merge | Merge job for JSON and XML. |
| source_reorganize | Data reorganize job for all sources. |
| source_reconcile | Data reconciliation job for RDBMS. |
Ingestion Notification Services
Source Level Notifications
- In the Source Settings page, click Add New Subscriber button.
- Enter the email ID of the subscriber.
- Select the Notify Via options which include email and slack.
- Select the jobs for which the subscriber must be notified. The jobs include fetch metadata and deletion of source.
- Click Save. The subscriber will be notified for the selected jobs.
Table Level Notifications
- In the Table Configuration page, click Add New Subscriber button.
- Enter the email ID of the subscriber.
- Select the Notify Via options which include email and slack.
- Select the jobs for which the subscriber must be notified. The jobs include crawl, reconciliation, reorganization and export of table.
- Click Save. The subscriber will be notified for the selected jobs.